1 Introduction
In previous posts we have explored ideas on how to construct fundamental models for forecasting the price of corn and wheat. These models used as input parameters the stock-to-usage numbers calculated from the monthly WASDE reports together with the Dollar index, the mean value of crude in the previous month and the Ruble vs Dollar exchange rate. The aim of this report is to extend these results to a spread between two related commodities, in this case corn and Kansas City Wheat. We use the shorthand C vs KW for this pair.
When we calculate the price difference between two commodities in the strategy Commodity 1 vs Commodity 2 we follow the convention
\[ S^A = P^A_2 - P^A_1 \] where \(P^A_i\) is the price of contract with symbol \(A\) for commodity \(i\). After all the spreads have been calculated we associate the spreads between two consecutive WASDE reports with the timestamp of the first report. This way we assume that the WASDE reports reflect reality with repect to the underlying fundamentals and we want to study the subsequent spread behaviour. Similar to the spread convention we use the difference between the two fundamentals defined by
\[ \delta = F_2 - F_1. \] Here \(F_i\) is the value of the particular fundamental of commodity \(i\). In this example we use stock-to-usage values. We collect all the different \(\delta\) values ang group them into decile buckets. This amounts to dividing all the different \(\delta\)’s into ten bucket all containing more or less the same number of entries. Withing these decile buckets we then calculate statistics on the spreads \(S^A\).
The different plots below show the spread statistics of each commodity contract code calculated withing the fundamental buckets shown on the x-axis. The darker and ligher shaded regions show the 25th to 75th and 5th to 95th percentiles respectively. The solid black lines shows the median spread. The latest value and associated decile bucket of the spread is indicated by the red point on each of the facets. From the plots below we can see that the C vs KW spread is on the lower range of the spread values given the current fundamentals.

Another way to look at the prices of two related commodities is the calculate their price ratios. Similar to the spreads we use the convention
\[ R^A = P^A_2/P^A_1 \] to calculate the ratio of prices between commodities 1 and 2. Continuing with this convention we define the fraction of fundamentals as
\[ \phi = F_2 / F_1. \]
We then follow in exactly the same way we did in the case of the spreads, except we calculate statistics of the price ratios \(R^A\) within each of the decile buckets of the fundamental ratios \(\phi\). The interpretation of the plots below are the same of those of the spread case. Notice that when we express the relative value in terms of a price ratio it is trading at an even greater discount.
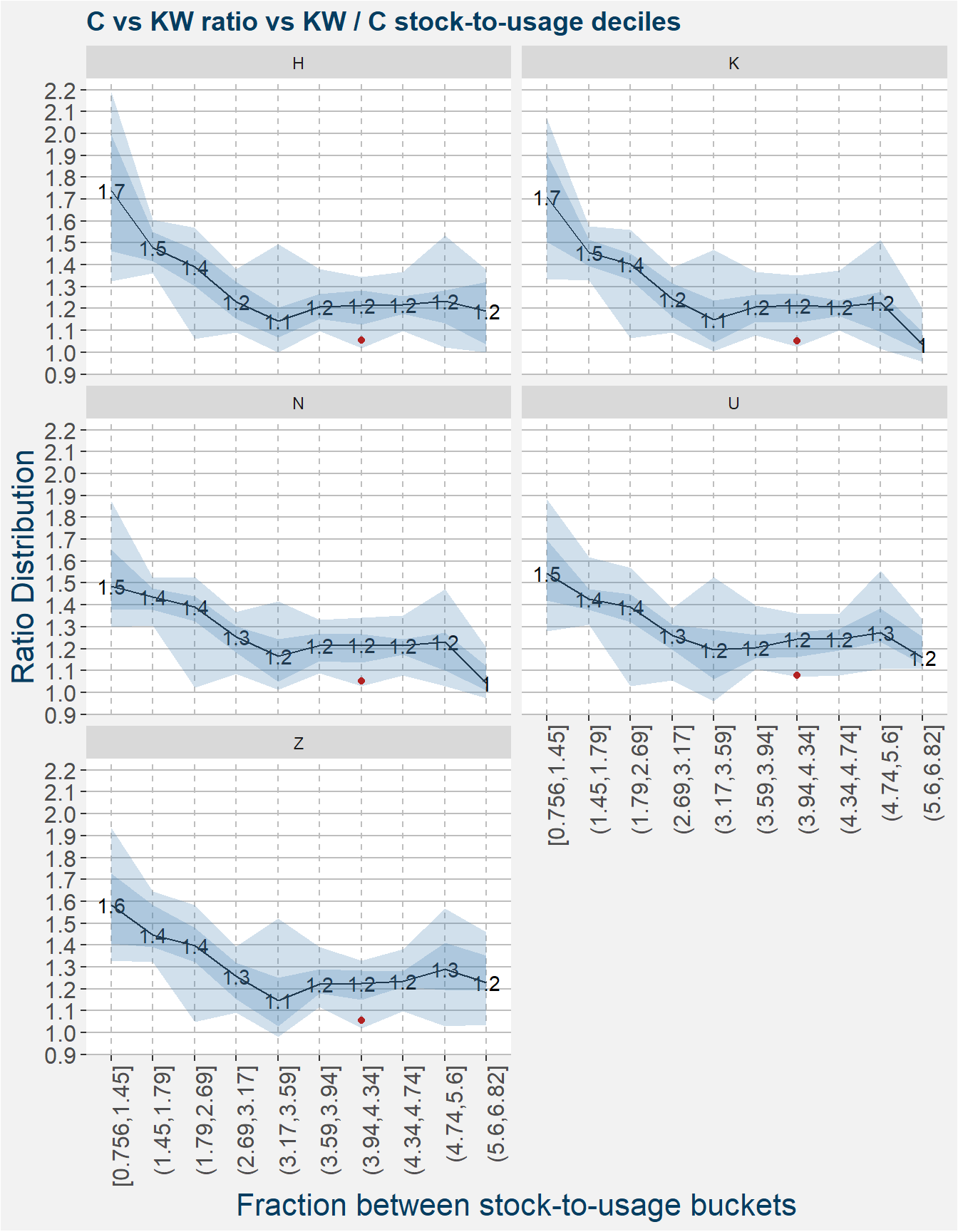
The plots above can give us a quick idea whether the current values of the spreads or ratios are trading at a premium or discount with respect the the prevailing stock-to-usage numbers reported by the USDA in the monthly WASDE report.
In the following we include more fundamental features in an attempt to incorporate some interaction terms that might be present. Below is a list of new features we include:
- daysdiff - the number of days left until the contract expired
- product - the product of the two stock-to-usage numbers
- comdty1 - stock-to-usage of commodity 1, C is this case
- comdty2 - stock-to-usage of commodity 2, KW in this case
- lagged features - denoted by lag 1 where we include the results from the previous report
- delta - absolute changes between current and lagged values
- per - percentage changes between current and lagged values
2 Modeling the Spread
In a previous post we showed some examples how we use techiniques from machine learning in out investment process. One techinique we find particularly interesting is the study of feature importance when using random forests in the modelling process. Similar to what we have done in previous posts (here, here and here) we explore the importance of each of the features we have used in the modelling process.
The barplots below show the feature importance of each of the input features for the different contract codes. The feature with greatest importance is highlighted in orange. The dashed red line shows the value of importance if all the features were equally important. It is interesting to note that the difference feature gives the best results for the majority of cases.

The plot below shows the aggregated feature importance values. From this plot it is even more clear the the difference feature clearly dominated the predictive power of the model.

The table below shows the model fit statistics for each contract code.
| code | R squared | mean cv score | std cv test score |
|---|---|---|---|
| H | 0.6583677 | 0.1830473 | 0.1566635 |
| K | 0.7242543 | 0.3651528 | 0.1377602 |
| N | 0.6403026 | 0.2974471 | 0.1209307 |
| U | 0.5456137 | 0.2720972 | 0.1660471 |
| Z | 0.4422226 | 0.1952217 | 0.1860956 |
The model predictions together with the latest values of the spreads are shown in the plot below. The shaded regions shows the 25th to 75th percentile of the model predictions. Median predictions are represented by the solid black line. Current C vs KW spread values are shown by the red dots. Notice that all the spreads, except that of U, is containing within the model error brackets. They are all on the lower en of the forcasted range.
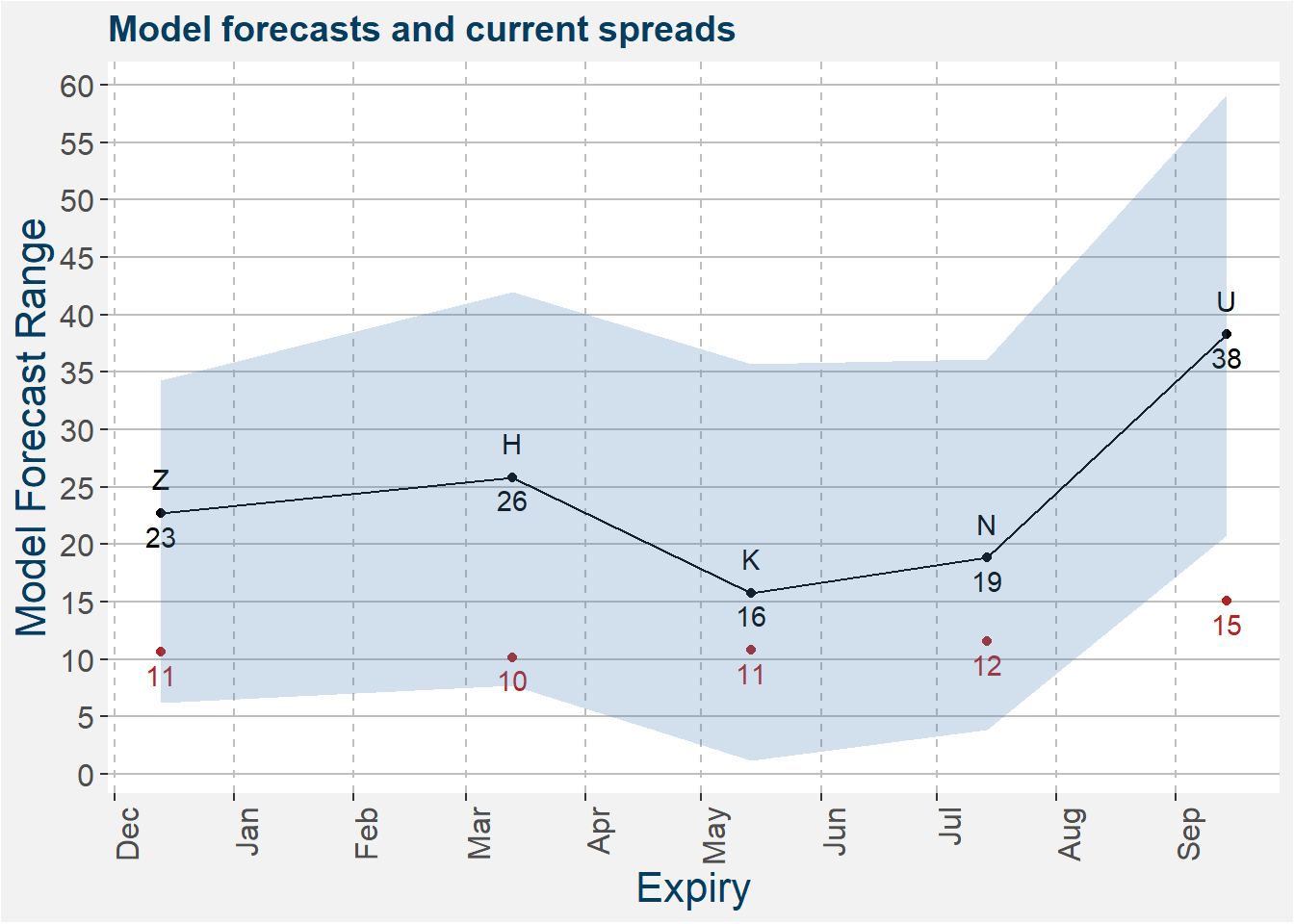
3 Modeling the Ratio
This section follows the same outline as the previous section with the exception that we replace the spread with the ratio. The barplots below show the feature importance of each of the input features for the different contract codes. The feature with greatest importance is highlighted in orange. The dashed red line shows the value of importance if all the features were equally important. It is interesting to note that the fraction feature gives the best results for the majority of cases.
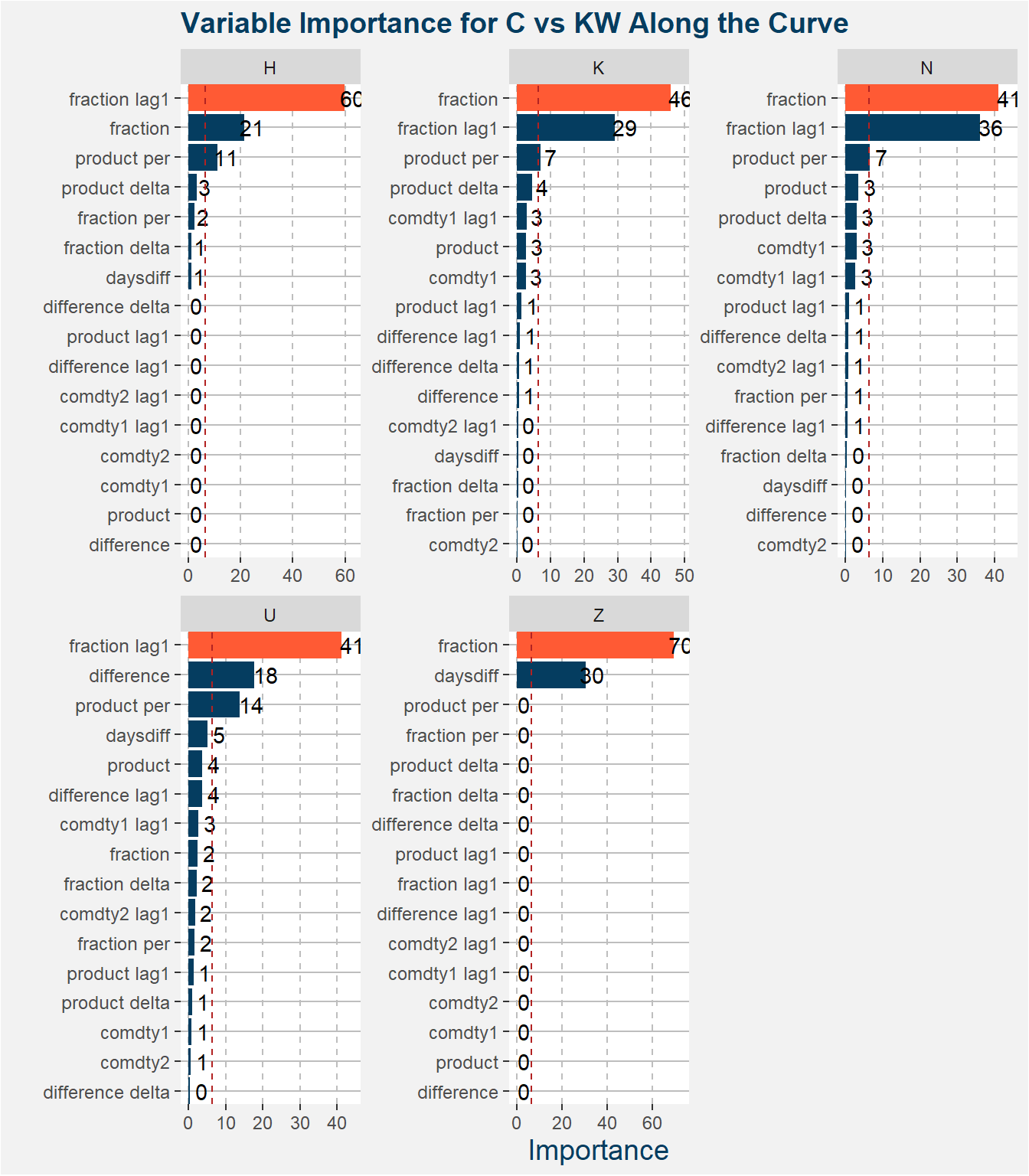
The plot below shows the aggregated feature importance values. From this plot it is even more clear the the fraction and fraction lag1 features clearly dominated the predictive power of the model. It is alos interesting to note that the daysdiff feature comes into play here which might imply that the spread has some kind of seasonal behaviour that we might be able to exploit.

The table below shows the model fit statistics for each contract code.
| code | R squared | mean cv score | std cv test score |
|---|---|---|---|
| H | 0.5245164 | 0.0578302 | 0.1690862 |
| K | 0.7447081 | 0.1902235 | 0.2421096 |
| N | 0.6819452 | 0.1614811 | 0.2156887 |
| U | 0.4352433 | 0.1190566 | 0.1561977 |
| Z | 0.3166329 | 0.1418705 | 0.1351991 |
The model predictions together with the latest values of the ratios are shown in the plot below. The shaded regions shows the 25th to 75th percentile of the model predictions. Median predictions are represented by the solid black line. Current C vs KW ratio values are shown by the red dots. The Z9 spreads do not have time on their hands but the other spreads have a little more time to play with. The H0 an U0 spread seem to show the greatest opportunity below.

4 Roll Structure
From the modelling of the spread and ratio is seems like there might be an opportunity being long the spread, i.e. long KW and short C. In this section we explore how this structure rolls. Throughout we assume a long position in KW and a short position in C. We also assume a 1:1 ratio when trading this relative, i.e. long one unit of KW and short one unit of C. We only consider data from 1 Jan 2009 onward to move the possible influence of the broken KW contract. In the facet plot below we show the ETF price and Cummulative Roll Gaps on the left and right respectively. The ETF price shows the value of $1 invested in the spread at the beginning of the time series. The Cummulative Roll Gaps shows the cummulative difference in price (USD/mt) when the structure is rolled forward. Note that the shape of the Cummulative Roll Gaps greatly determines the shape of the evolution of the ETF price. This is the case for most relative value pairs where the term structure of the different commodities plays a major role in the overall return profile. From the data is it clear that sustained periods of positive return coinside with periods where the Cummulative Roll Gaps has a zero or positive slope.
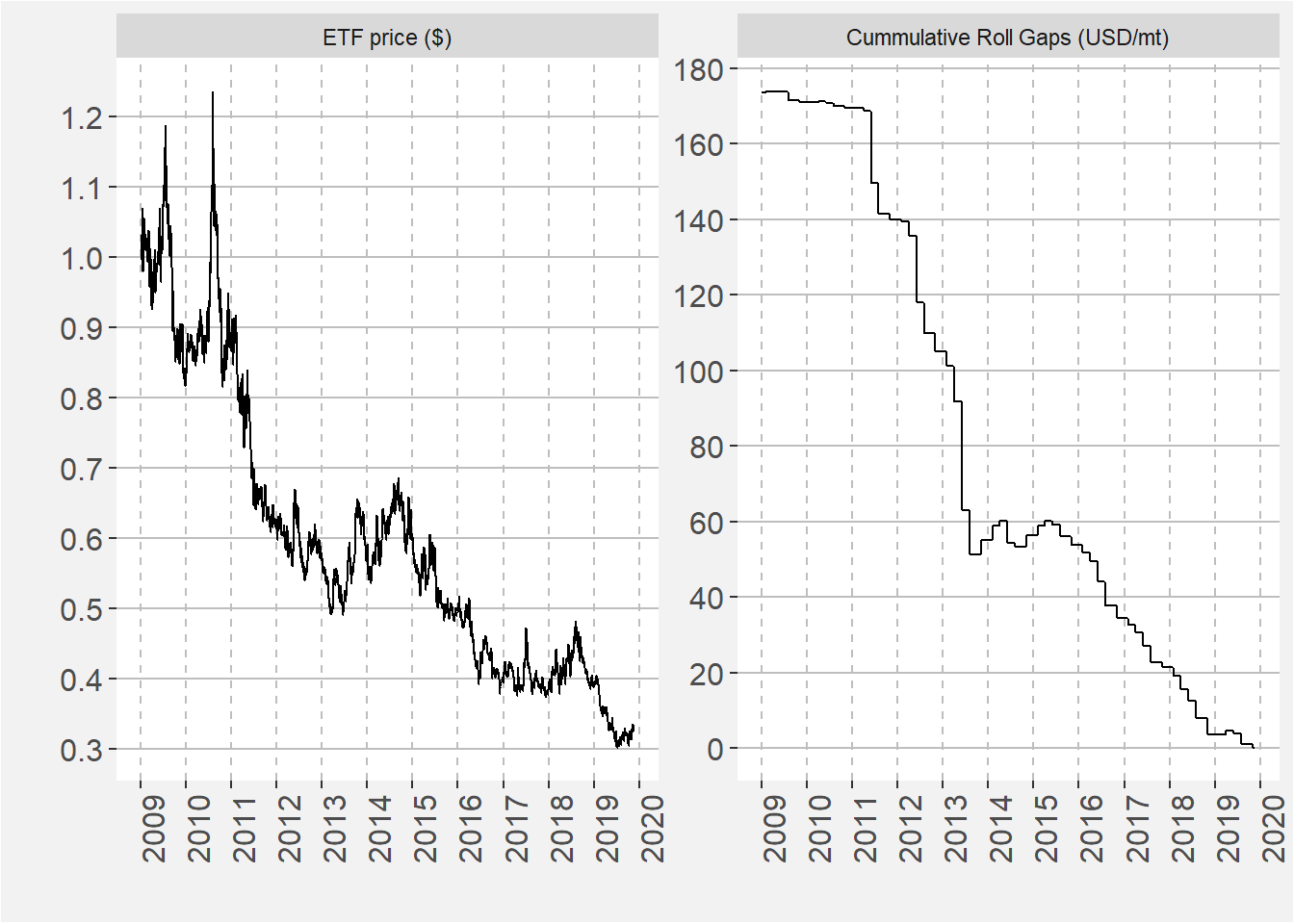
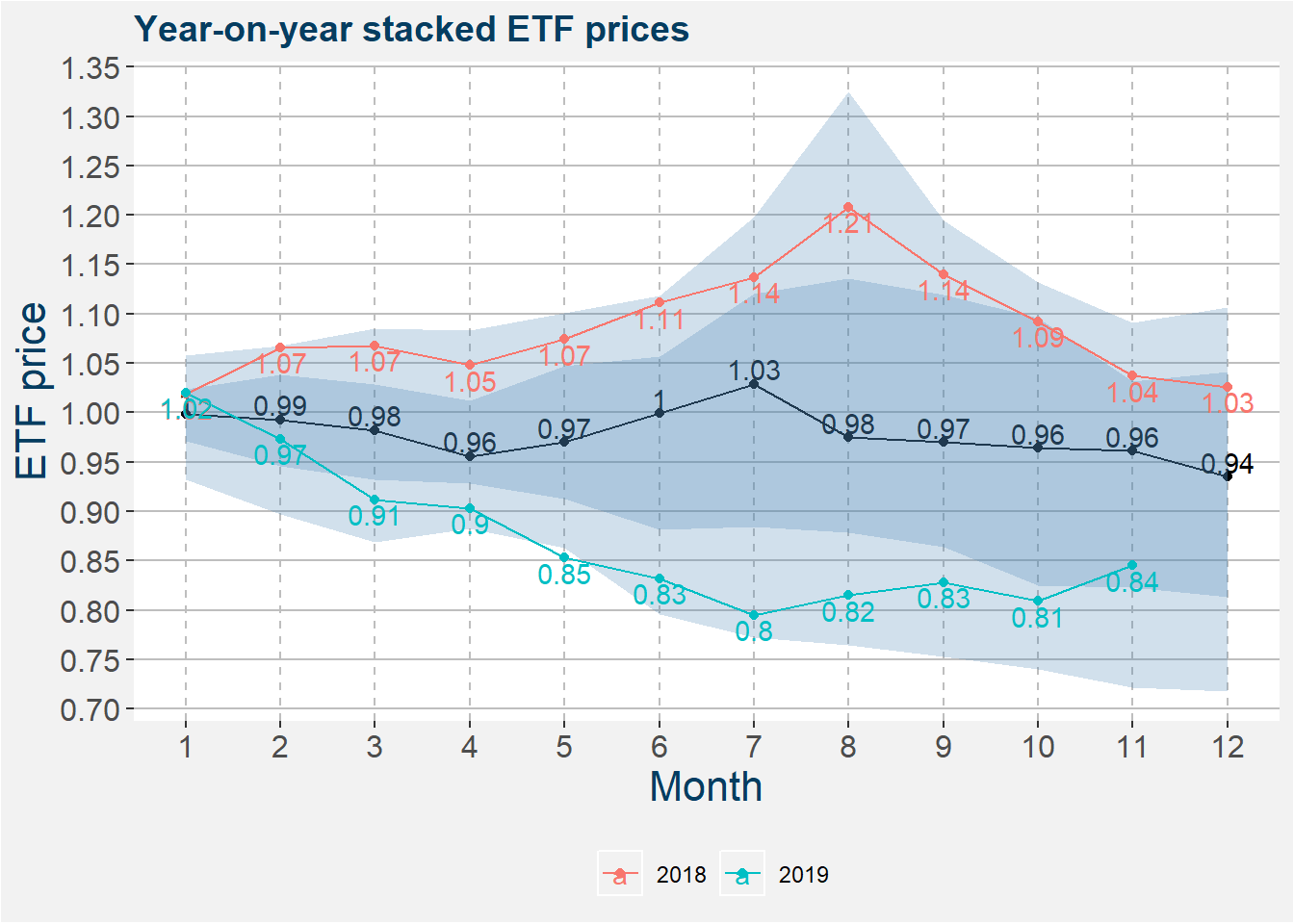
The plot below takes the ETF price data and stackes the normalised data together from the 1st of January to the 31 of December for each year. Within each month we calculate statistics. The 25th to 75th and 5th to 95th percentiles are given by the darker and ligher shaded regions respectively. The median yearly return is represented by the solid black line.. Superimposed on top of the universe ribbon plot the the data for 2018 and as well as 2019. From the plot it is clear that under normal circumstances we can expect to pay away 6% of the capital allocated to this strategy on a yearly basis.
Below we show the futures curves of C and KW. In order to have a flat or positive roll yield we require the curve of the long commodity (KW) to have a slope that is less than that of the short commodity (C). By eye we can see that the KW curve is steeper than the C curve, this does not give a favourable roll situation.
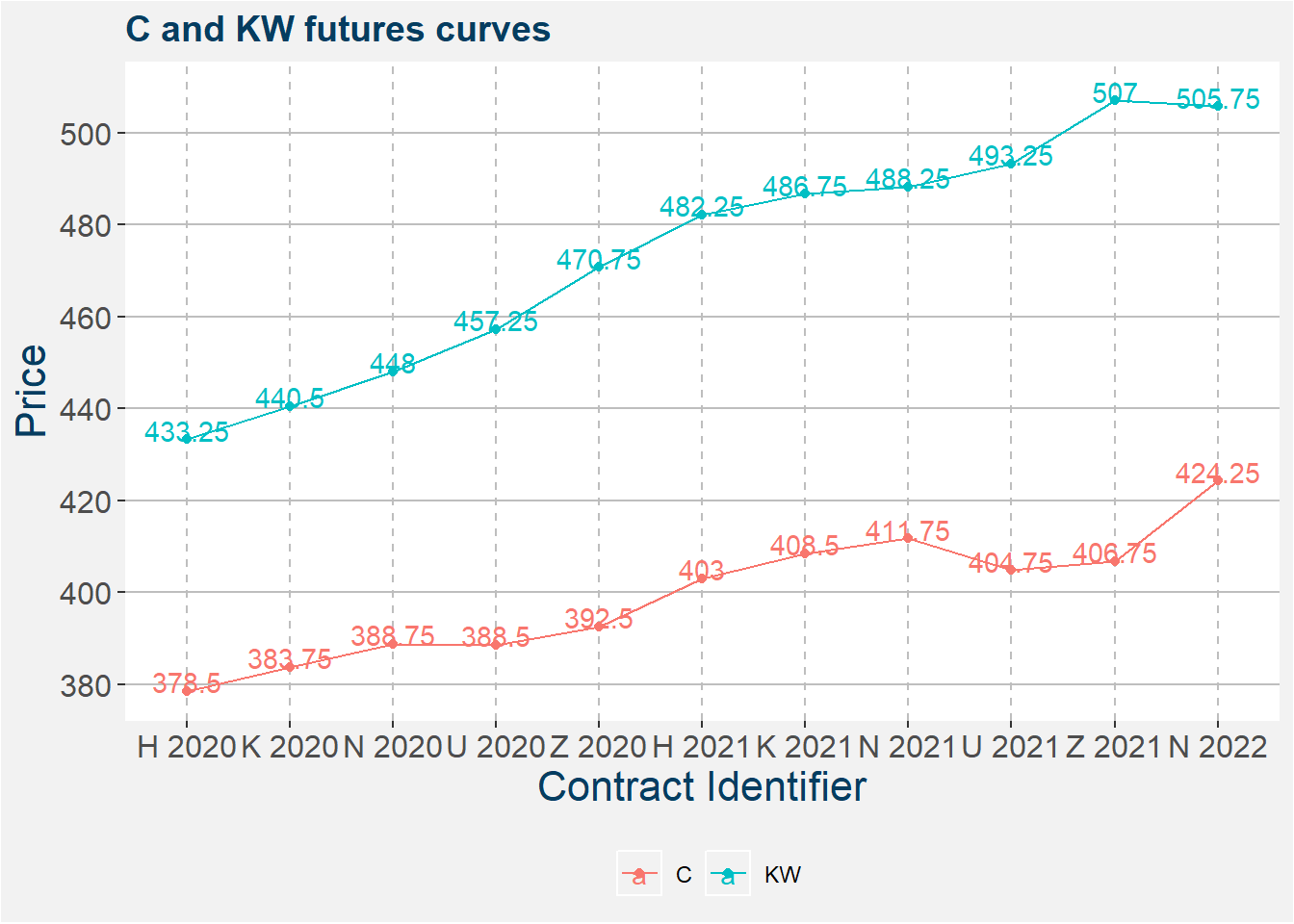
The table below summarises the results. The columns are pretty self-explanatory, save for C change and KW change which show the differnce between consecutive prices, i.e. the value of the calendar spread. The Roll Yield the difference between the change in C and KW. If the roll yield is positive it indicates favourable roll period. Note that currently the Roll Yields are not favourable.
| identifier | daysdiff | C price | KW price | C change | KW change | Roll Yield |
|---|---|---|---|---|---|---|
| H 2020 | 98 | 378.50 | 433.25 | NA | NA | NA |
| K 2020 | 160 | 383.75 | 440.50 | 5.25 | 7.25 | -2.00 |
| N 2020 | 221 | 388.75 | 448.00 | 5.00 | 7.50 | -2.50 |
| U 2020 | 283 | 388.50 | 457.25 | -0.25 | 9.25 | -9.50 |
| Z 2020 | 374 | 392.50 | 470.75 | 4.00 | 13.50 | -9.50 |
| H 2021 | 462 | 403.00 | 482.25 | 10.50 | 11.50 | -1.00 |
| K 2021 | 525 | 408.50 | 486.75 | 5.50 | 4.50 | 1.00 |
| N 2021 | 586 | 411.75 | 488.25 | 3.25 | 1.50 | 1.75 |
| U 2021 | 648 | 404.75 | 493.25 | -7.00 | 5.00 | -12.00 |
| Z 2021 | 739 | 406.75 | 507.00 | 2.00 | 13.75 | -11.75 |
| N 2022 | 951 | 424.25 | 505.75 | 17.50 | -1.25 | 18.75 |
Note that the roll yield is the idfference between to calendar spreads. In the following se use corn and Kanasas wheat stock-to-usage to model the different calendarspread involved in the roll process. In this way, if we have to fundamental point of view on the underling stock-to-usage values we can get an idea of how the spread as well as the roll will be affected.
4.1 Corn Calendars
Below we show the spread statistiscs of the corn calendar spreads making up the roll process. From the plots below there is not a great amount of structure in the HK and ZH calendars spreads, the other spreads have better strucutre and will be easier to model. As beofe the current values of the spreads are indicated by the red dots.

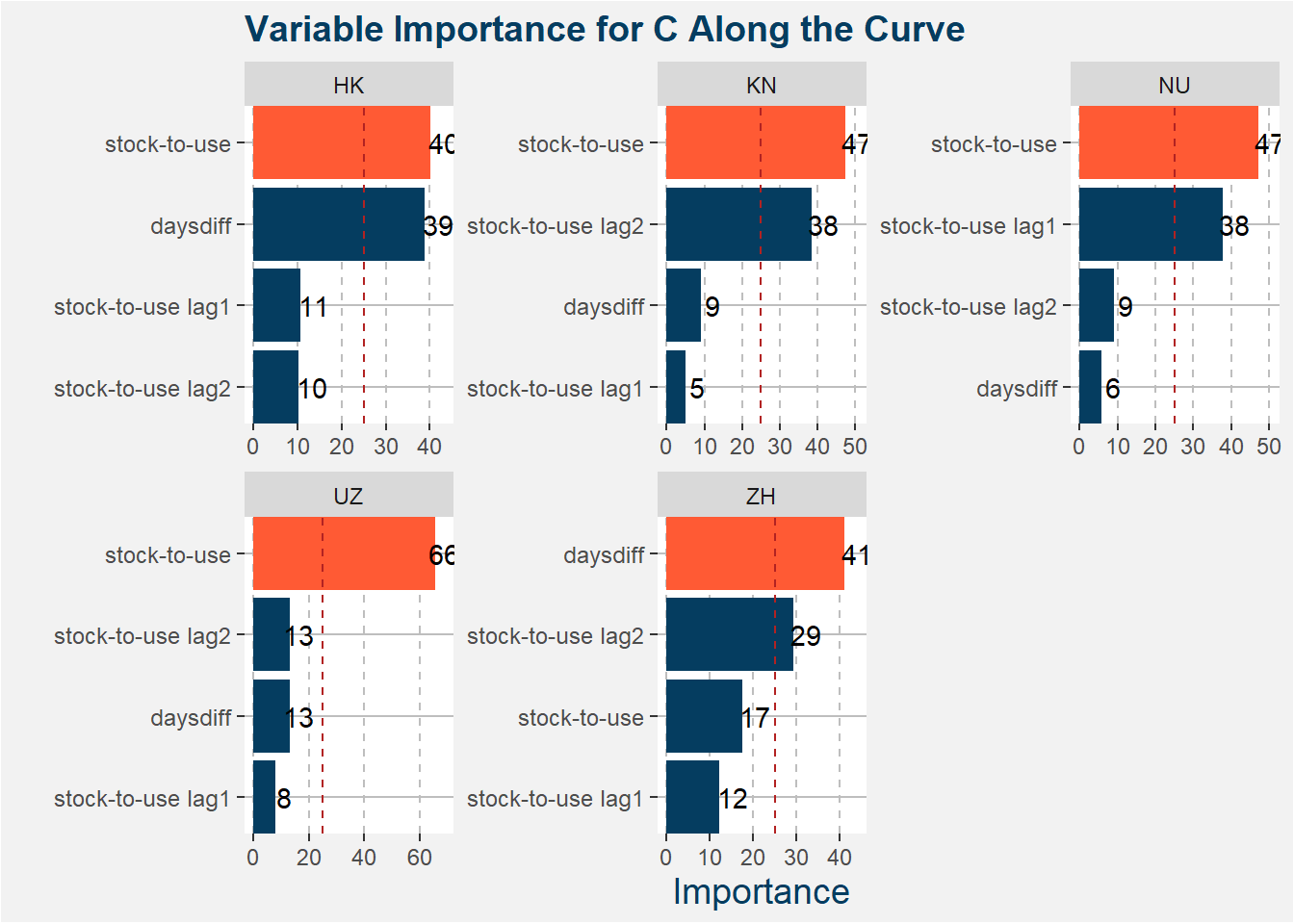
Below we show the feature importances for each of the calendar spreads. We can see that the stock-to-usage and daysdiff features play the biggest roles in the predictive models.
| calRef | R squared | mean cv score | std cv test score |
|---|---|---|---|
| HK | -0.5132399 | -0.5145170 | 0.4259837 |
| HN | -0.7342162 | -0.6300058 | 0.6276842 |
| KN | -0.2905441 | 0.0683175 | 0.0352093 |
| NU | 0.6387132 | 0.4719729 | 0.1340568 |
| NZ | 0.7442544 | 0.5413220 | 0.1228094 |
| UH | 0.3706887 | 0.5161783 | 0.1170007 |
| UZ | 0.4542380 | 0.5747438 | 0.1257030 |
| ZH | 0.2349001 | -0.1394719 | 0.2145619 |
| ZN | -0.0539839 | -0.3896314 | 0.4762933 |
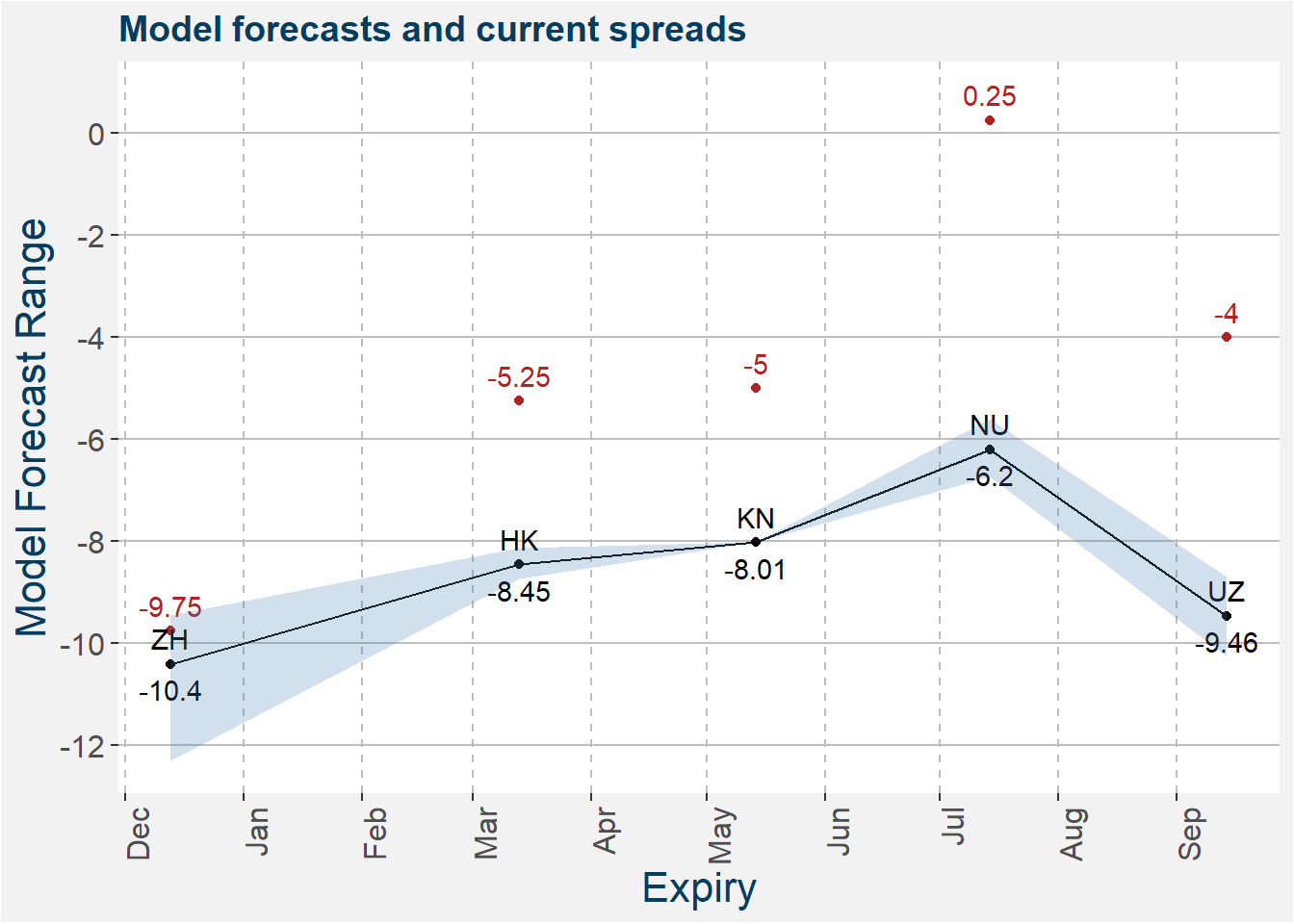
The model predictions together with the latest values of the spreads are shown in the plot below. The shaded regions shows the 25th to 75th percentile of the model predictions. Median predictions are represented by the solid black line. Current C calendar spread values are shown by the red dots. The ZH calendar spread is almost at expiry and has collapsed to within the blue shaded region. The other calendar spread show some potential to become more contango if the current stock conditions remain unchanged.
Below we show the calendar spread model sensitivities. These plots measure how a change in the stock-to-usage affects the model prediction of the spread. Similar to before the shaded region represents the 22th to 75th percentile of the model predictions with the median represented by the solid black line. The mean is given by the dashed red line. Here we set the daysdiff feature to 10 days prior to expiry.

4.2 Kansas Wheat Calendars
Below we show the spread statistiscs of the Kansas wheat calendar spreads making up the roll process. As beofe the current values of the spreads are indicated by the red dots.
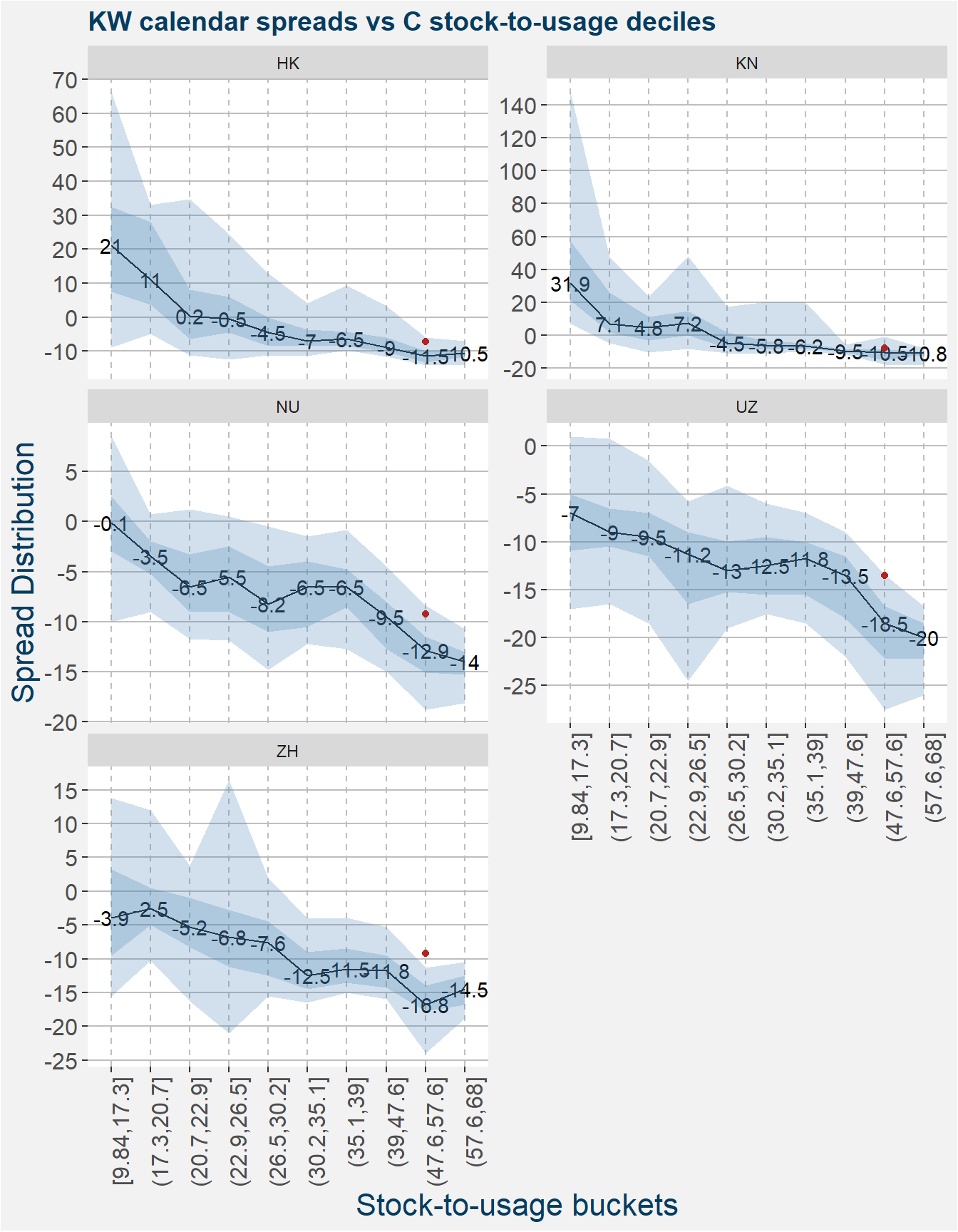
Below we show the feature importances for each of the calendar spreads. We can see that the stock-to-usage and daysdiff features play the biggest roles in the predictive models.

| calRef | R squared | mean cv score | std cv test score |
|---|---|---|---|
| HK | 0.6929417 | 0.2343143 | 0.0810083 |
| HN | 0.7914282 | 0.6067151 | 0.0875554 |
| KN | 0.7471559 | 0.5607929 | 0.0939439 |
| NU | 0.5264079 | 0.4921912 | 0.1099332 |
| NZ | 0.4210873 | 0.5537511 | 0.1088819 |
| UH | 0.6139483 | 0.2416494 | 0.1159706 |
| UZ | 0.5041719 | 0.2001270 | 0.1357214 |
| ZH | 0.3834168 | 0.1845505 | 0.2311144 |
| ZN | 0.7459341 | 0.4997087 | 0.1664777 |
The model predictions together with the latest values of the spreads are shown in the plot below. The shaded regions shows the 25th to 75th percentile of the model predictions. Median predictions are represented by the solid black line. Current KW calendar spread values are shown by the red dots. The ZH calendar spread is almost at expiry.
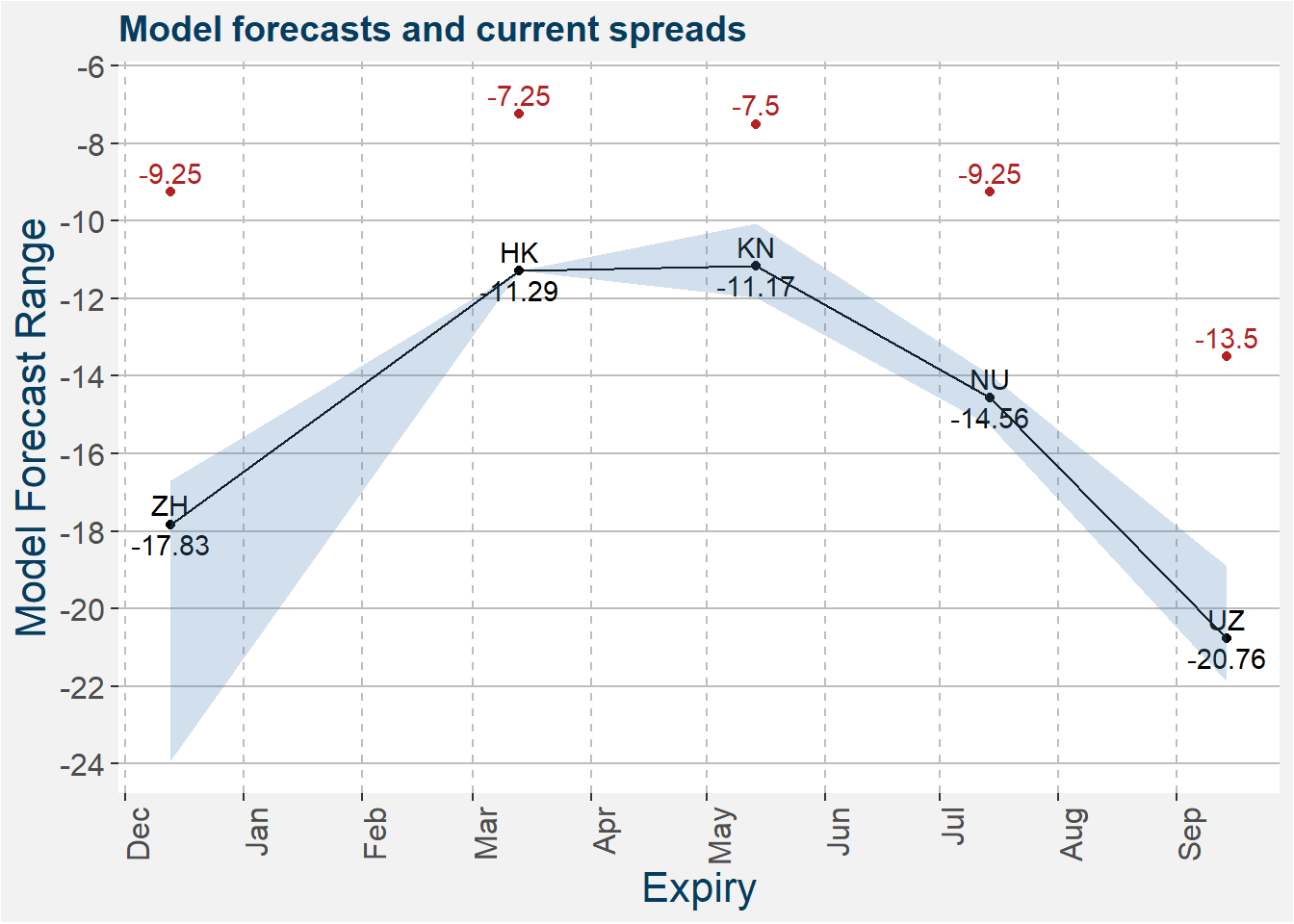
Below we show the calendar spread model sensitivities. These plots measure how a change in the stock-to-usage affects the model prediction of the spread. Similar to before the shaded region represents the 22th to 75th percentile of the model predictions with the median represented by the solid black line. The mean is given by the dashed red line. Here we set the daysdiff feature to 10 days prior to expiry.
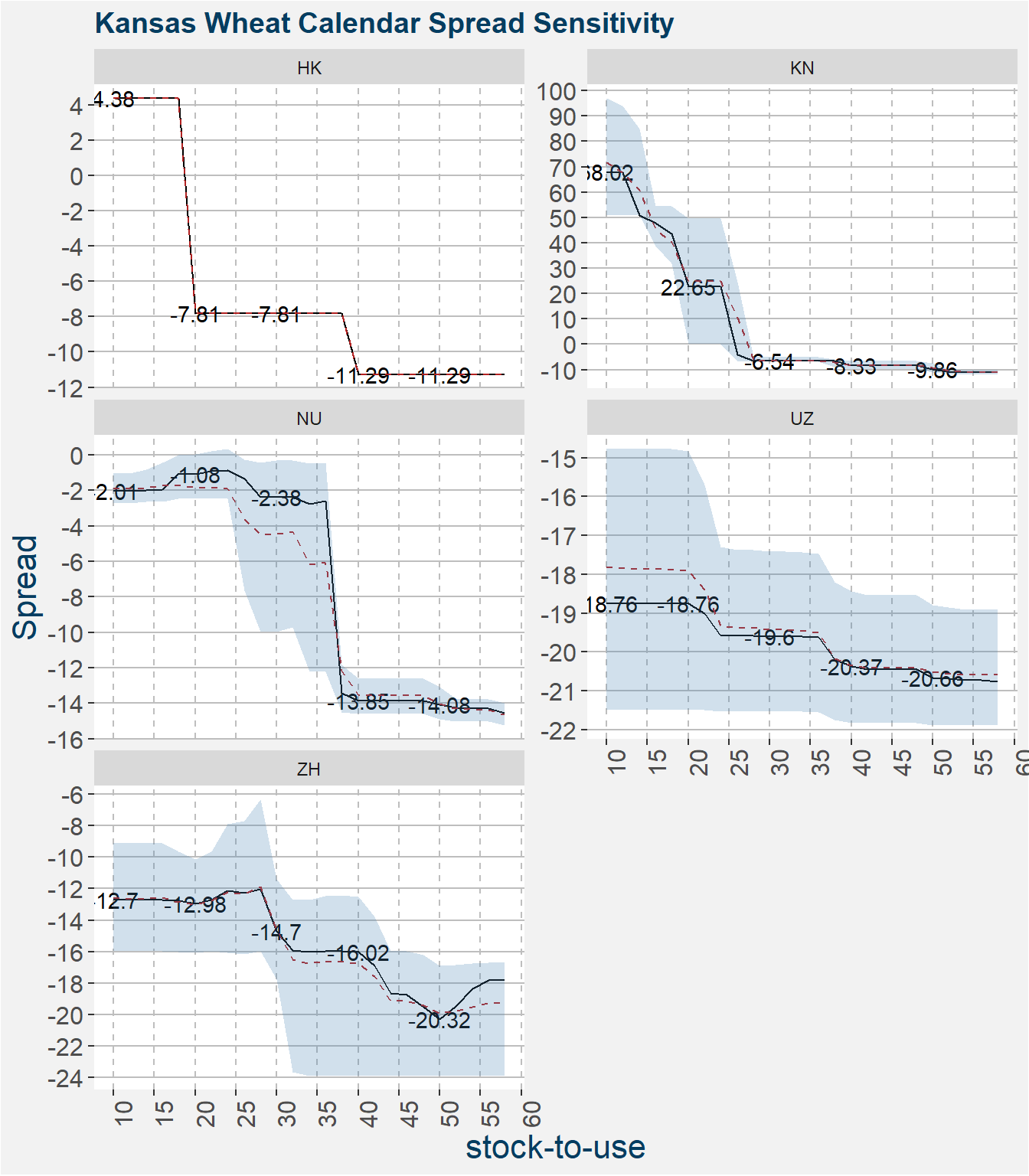
5 Hypothetical Scenario
Suppose we are of the view that
- Kansan stock-to-usage will be around 45
- Corn stock-to-usage will be around 20
- The difference is then 25
We are interested to trade this spread on the long side, i.e. long KW and short C from H20 through to U20. The table below gives a rough idea of where the different spreads are expected to settle when the difference in stock-to-usage is 25.
| code | cat | p05 | p25 | med | p75 | p95 | N | current spread | difference | to median |
|---|---|---|---|---|---|---|---|---|---|---|
| H | (23.2,25.5] | 10.13 | 45.86 | 58.22 | 76.38 | 97.19 | 222 | 10.18 | 25 | 48.04 |
| K | (23.2,25.5] | 9.16 | 39.50 | 49.14 | 62.12 | 78.72 | 237 | 10.78 | 25 | 38.36 |
| N | (23.2,25.5] | 9.11 | 39.16 | 48.71 | 60.21 | 76.78 | 253 | 11.57 | 25 | 37.14 |
| U | (23.2,25.5] | 38.61 | 50.04 | 66.71 | 77.93 | 96.06 | 244 | 15.06 | 25 | 51.65 |
Suppose we aim to retrieve the average of the spread moved toward the median, this amounts to 43.8 USD/mt. The calendar spread predictions under the stock-to-usages mentioned above are given in the table below.
| calRef | cat | p05 | p25 | med | p75 | p95 | N | current spread | stock-to-use | comdty | conversion |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HK | (19.4,24.4] | -9.50 | -7.50 | -6.75 | -5.00 | -3.750 | 601 | -5.25 | 25 | C | 0.3936825 |
| KN | (19.4,24.4] | -10.50 | -8.00 | -6.75 | -5.00 | -3.000 | 581 | -5.00 | 25 | C | 0.3936825 |
| NU | (19.4,24.4] | -9.25 | -7.75 | -6.50 | -5.75 | 1.250 | 500 | 0.25 | 25 | C | 0.3936825 |
| HK | (39,47.6] | -11.75 | -10.25 | -9.00 | -6.00 | 3.300 | 437 | -7.25 | 45 | KW | 0.3674370 |
| KN | (39,47.6] | -11.75 | -10.25 | -9.50 | -8.50 | -5.675 | 515 | -7.50 | 45 | KW | 0.3674370 |
| NU | (39,47.6] | -15.00 | -12.75 | -9.50 | -8.00 | -4.500 | 503 | -9.25 | 45 | KW | 0.3674370 |
The table below shows the 25th, 50th and 75th percentile of the roll yields converted to USD/mt so that it is in the same units as the spread. Notice that you will pay away between 2 to 3 USD/mt to roll this spread forward from H to K.
| calRef | p25 | p50 | p75 |
|---|---|---|---|
| HK | -0.82 | -0.65 | -0.23 |
| KN | -0.62 | -0.83 | -1.15 |
| NU | -1.63 | -0.93 | -0.68 |
| total | -3.07 | -2.41 | -2.06 |
The plot below shows where the projected roll yield lie wihting the distribution of historical roll yields.
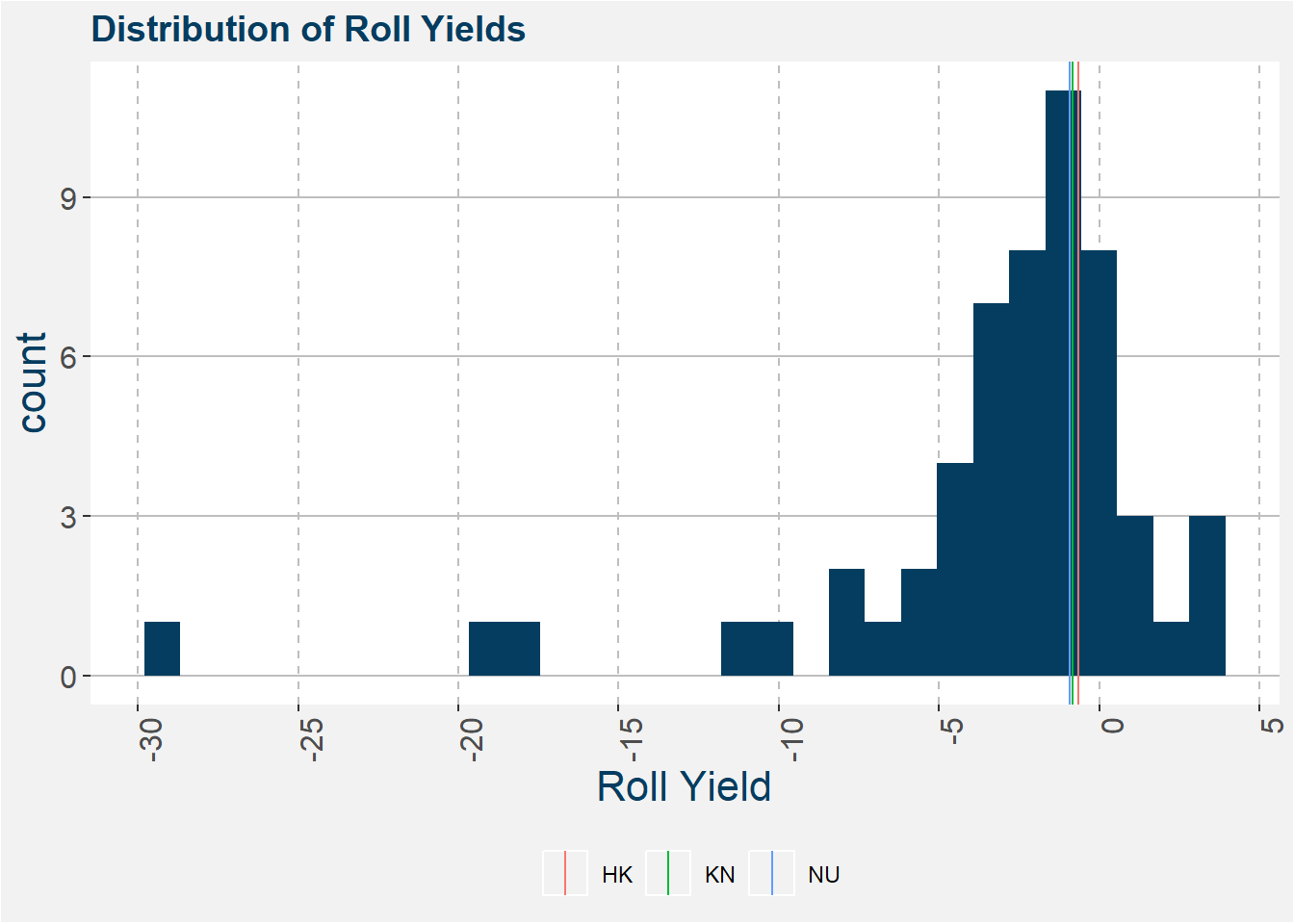
Under our assumptions we should expect to see a slighlty negative roll yield however the possible correction of the spread outweighs the negative roll.
6 Remarks
Given that the difference and fraction features showed the best predicting ability it makes sense to use the decile plots as a quick reference to see whether the prevailing spreads or ratios are trading at a premium or discount with respect to the underlying fundamentals.
If we have a fundamental view on the stock-to-usages of corn and Kansas wheat we can use those values to forecast where the spreads should be as well as the possible roll yield.