1 Introduction
Here we explore the viability of modelling the price of corn as a function of stock-to-usage. The market receives new information about the state of global stocks once a month after the WASDE reports have been published. As the global balance sheets change during the course of the season the expectation of the stock levels left over at the end of the season changes. We aim to model the corn price along the futures curve as a function of stock-to-usage percentages of the major producing and consuming nations. We add a proxy for energy by looking at the average WTI crude price during the prior month. Furthermore we also consider the dollar strength as measure by the dollar index.
The plot below shows the evolution of the corn stock-to-usage numbers for the United States and World levels.

We want to connect these stock-to-usage numbers with price of the corresponding corn futures contracts. To do this we connect the price data between two successive WASDE reports with the first report and aggregate the results. As an example consider two reports dated 2018-05-11 and 2018-06-12 respectively. All price data between those two dates are associated with the first date.
The images below give a graphical representation of the data. The x- and y-axes represent the Stock-to-Usage and Price of the July contract respectively.
From the images we can distinguish between two different regimes roughly corresponding to before and after 2007. This can be seen by the clear separation of the larger and smaller points in the plot below. I am not sure if there is some fundamental reason for the separation of not. It might have to do with pre and post GMO.
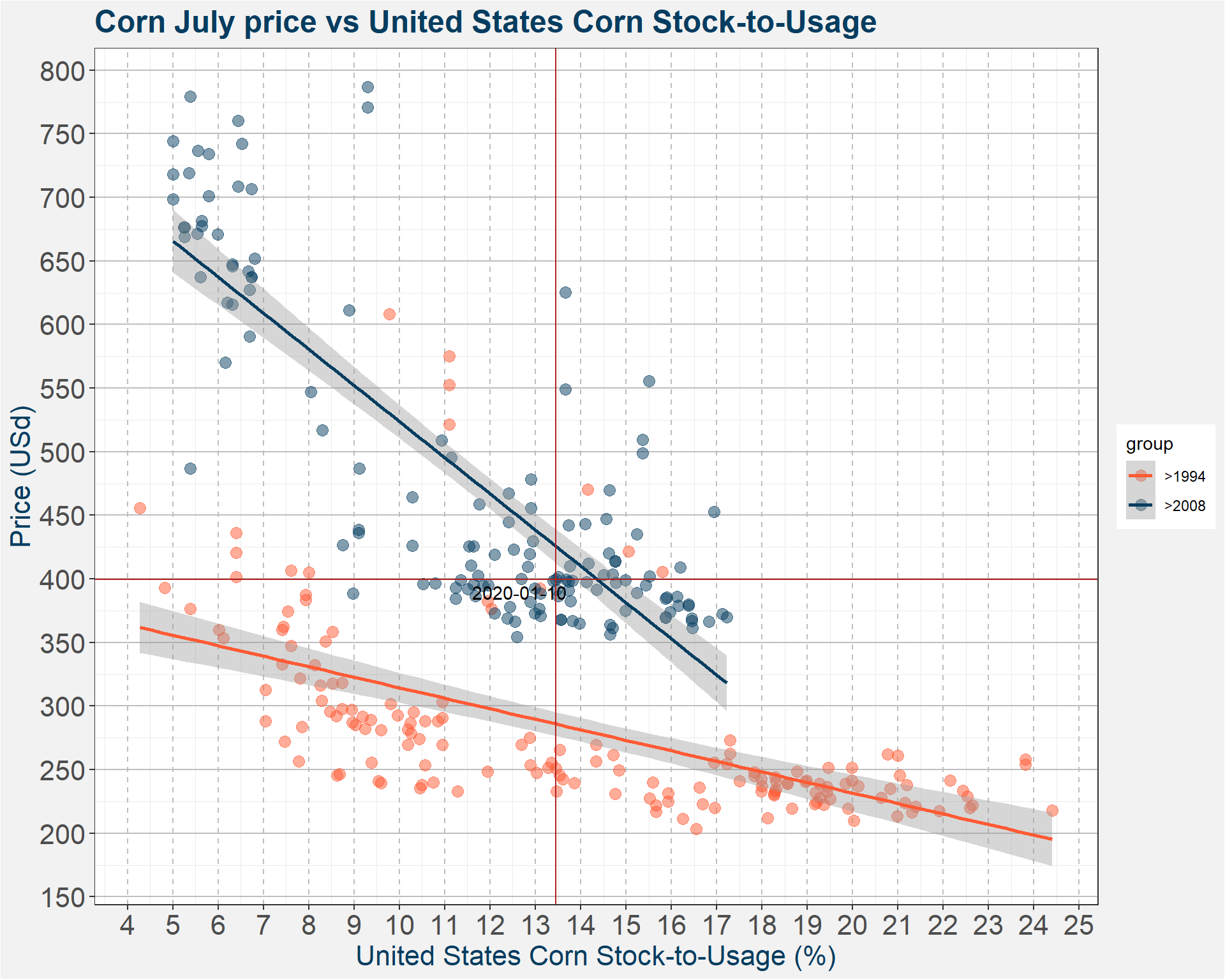
2 Deterministic Model
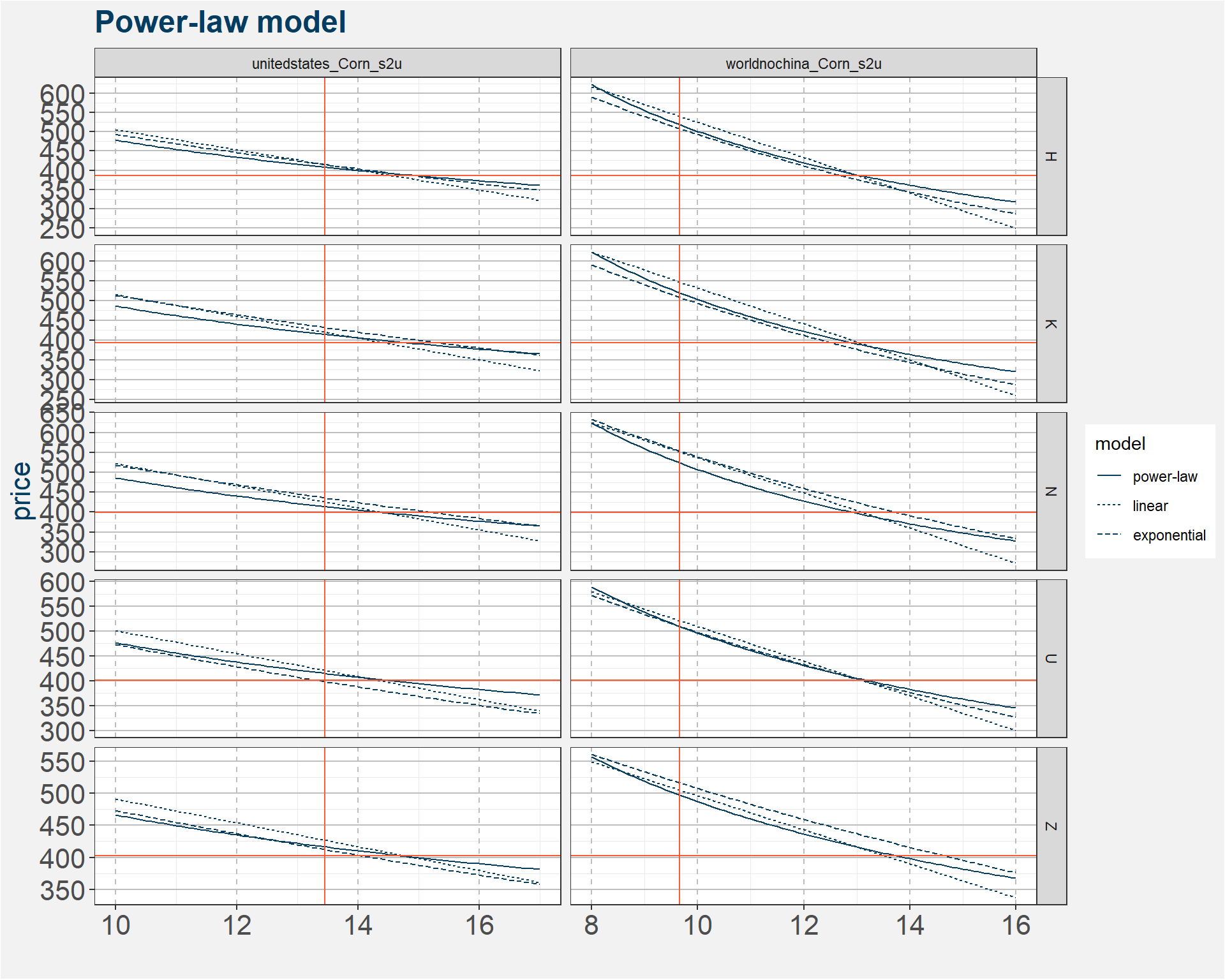
From the bubble chart above it looks like a linear model should be sufficient to model the July corn price as a function of stock-to-usage. Here we look at a couple slight modifications to improve upon the simple linear model. It looks like the data clumps together around $4 for stock-to-usages greter than 15. We see that the prices are decreasing at a slower rate with increasing stock-to-usage numbers. Linear models on the other hand assume a constant rate of decrease. Here we look at two alternative models, a power-law and exponential model, both of which have decreasing rates of change.
To find the best model it amounts to looking at the three different graphs below and deciding which has the best linear fit to the data. The equation describing the models are given below
Linear: \[ y = x \times m + c \]
Power-Law: \[ y = x^{m}\times \exp\left(c\right) \]
Exponential: \[ y = \exp\left( x \times m + c \right) \] In all three equations above \(x\) and \(y\) represent stock-to-usage and price respectively.
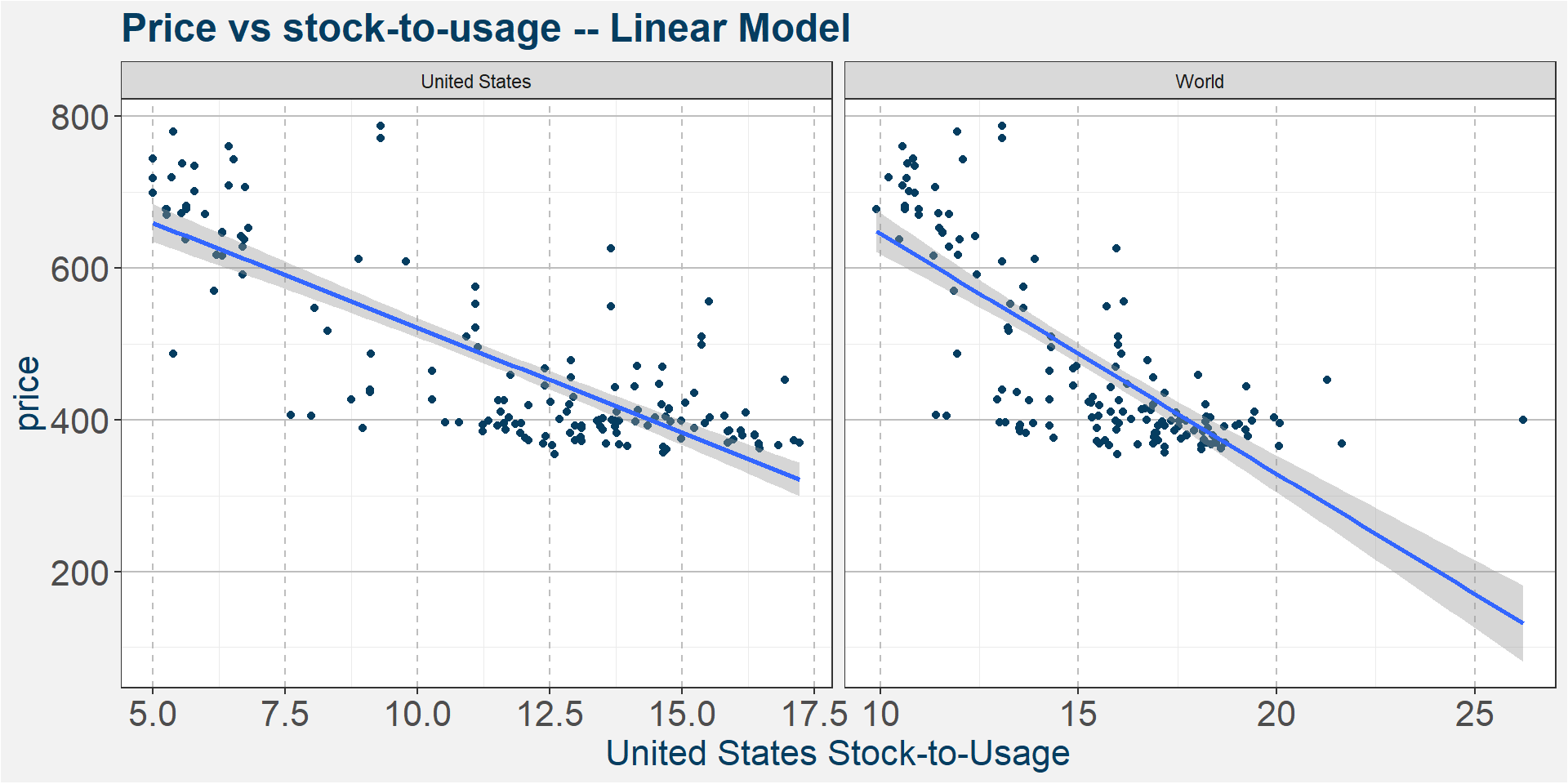
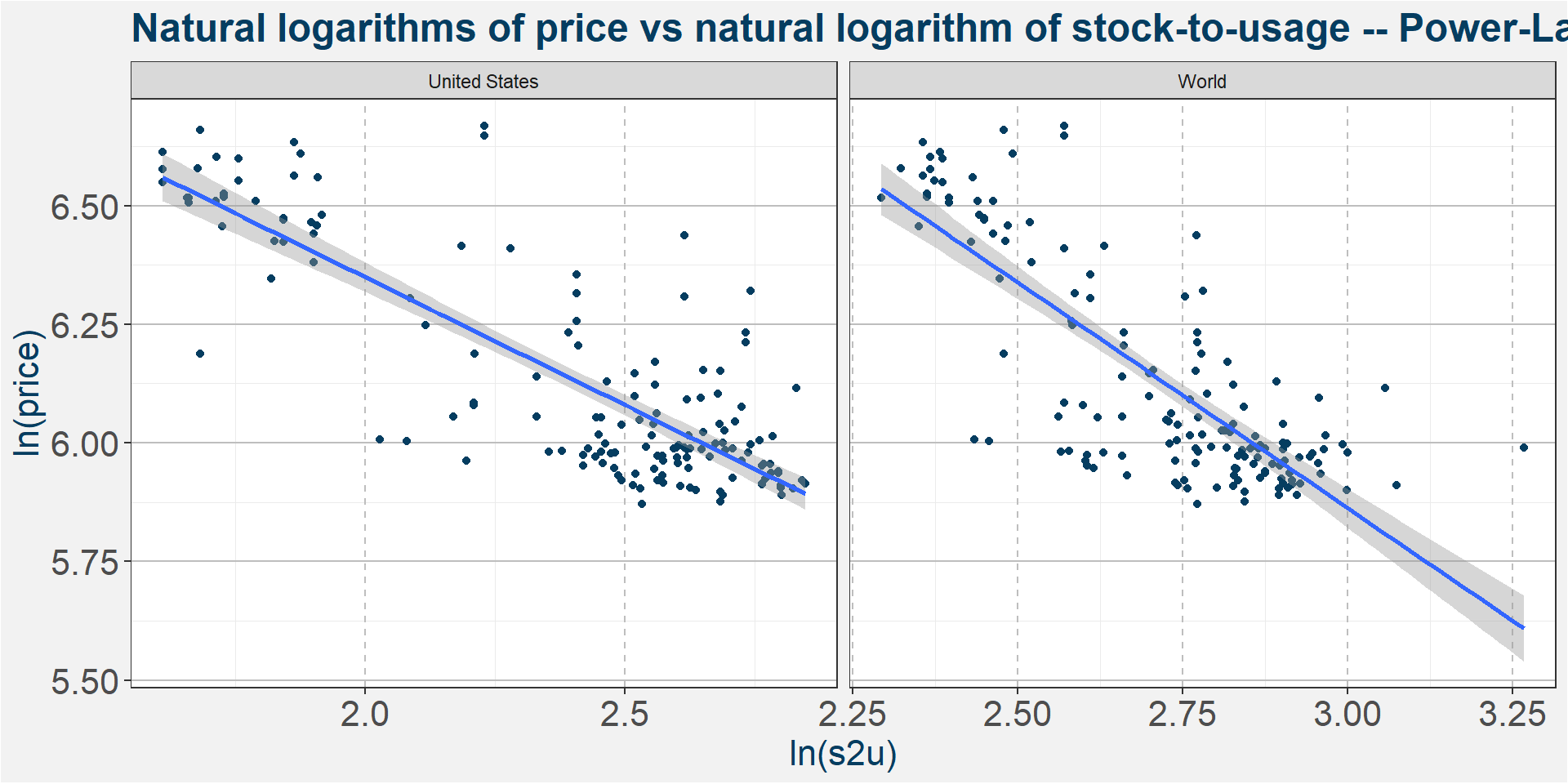
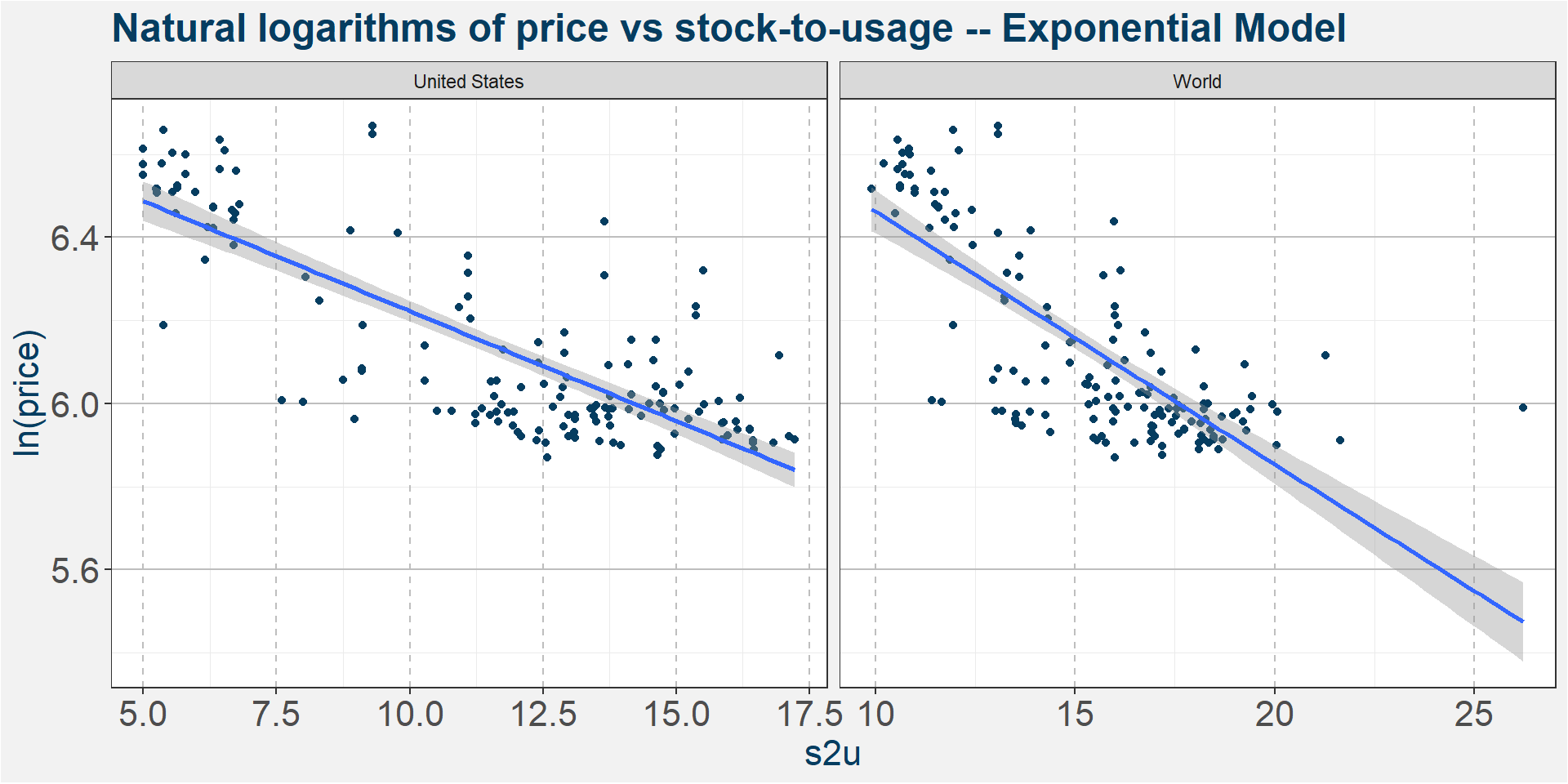
By eye the results look fairly similar. The table below summarises the results and provides the coefficients to plug into the model. The best fit models seems to be the Power-Law model. For best results we recommend averaging the results of the three models.
The table below summarises the results of the model fitting. Each cell shows the R-squared value of the fit. The models with the greatest R-squared values are shown at the top. From this naive in-sampe point of view we can see that United States Corn Stock-to-Usage is the best predictor followed by world and world withouth China Stock-to-Usages. The next most important features are Mean Month Prior Crude and the Dollar Index. In the following we have a closer look at the relationship between price and the main predictive features according to the table below.
| exponential | linear | power law | |
|---|---|---|---|
| unitedstates_Corn_s2u | 0.64 | 0.64 | 0.69 |
| world_Corn_s2u | 0.57 | 0.57 | 0.63 |
| worldnochina_Corn_s2u | 0.52 | 0.53 | 0.56 |
| crude | 0.51 | 0.48 | 0.48 |
| dollarindex | 0.40 | 0.38 | 0.41 |
| ruble | 0.32 | 0.30 | 0.33 |
| expiry | 0.14 | 0.13 | 0.13 |
| argentina_Corn_s2u | 0.12 | 0.12 | 0.09 |
| brazil_Corn_s2u | 0.07 | 0.06 | 0.09 |
| ukraine_Corn_s2u | 0.03 | 0.02 | 0.05 |
| china_Corn_s2u | 0.08 | 0.07 | 0.03 |
| russia_Corn_s2u | 0.03 | 0.03 | 0.02 |
The model coefficients are given in the table below.
| model | Rsq | m | c | code |
|---|---|---|---|---|
| linear | 0.55 | -26.09 | 765.87 | H |
| power law | 0.61 | -0.53 | 7.39 | H |
| exponential | 0.56 | -0.05 | 6.70 | H |
| linear | 0.61 | -27.47 | 789.43 | K |
| power law | 0.67 | -0.54 | 7.43 | K |
| exponential | 0.62 | -0.05 | 6.74 | K |
| linear | 0.64 | -27.63 | 797.42 | N |
| power law | 0.69 | -0.54 | 7.43 | N |
| exponential | 0.64 | -0.05 | 6.75 | N |
| linear | 0.70 | -23.15 | 732.56 | U |
| power law | 0.74 | -0.47 | 7.25 | U |
| exponential | 0.71 | -0.05 | 6.66 | U |
| linear | 0.76 | -18.64 | 677.61 | Z |
| power law | 0.78 | -0.38 | 7.02 | Z |
| exponential | 0.76 | -0.04 | 6.56 | Z |
2.1 Deterministic Model Sensitivity
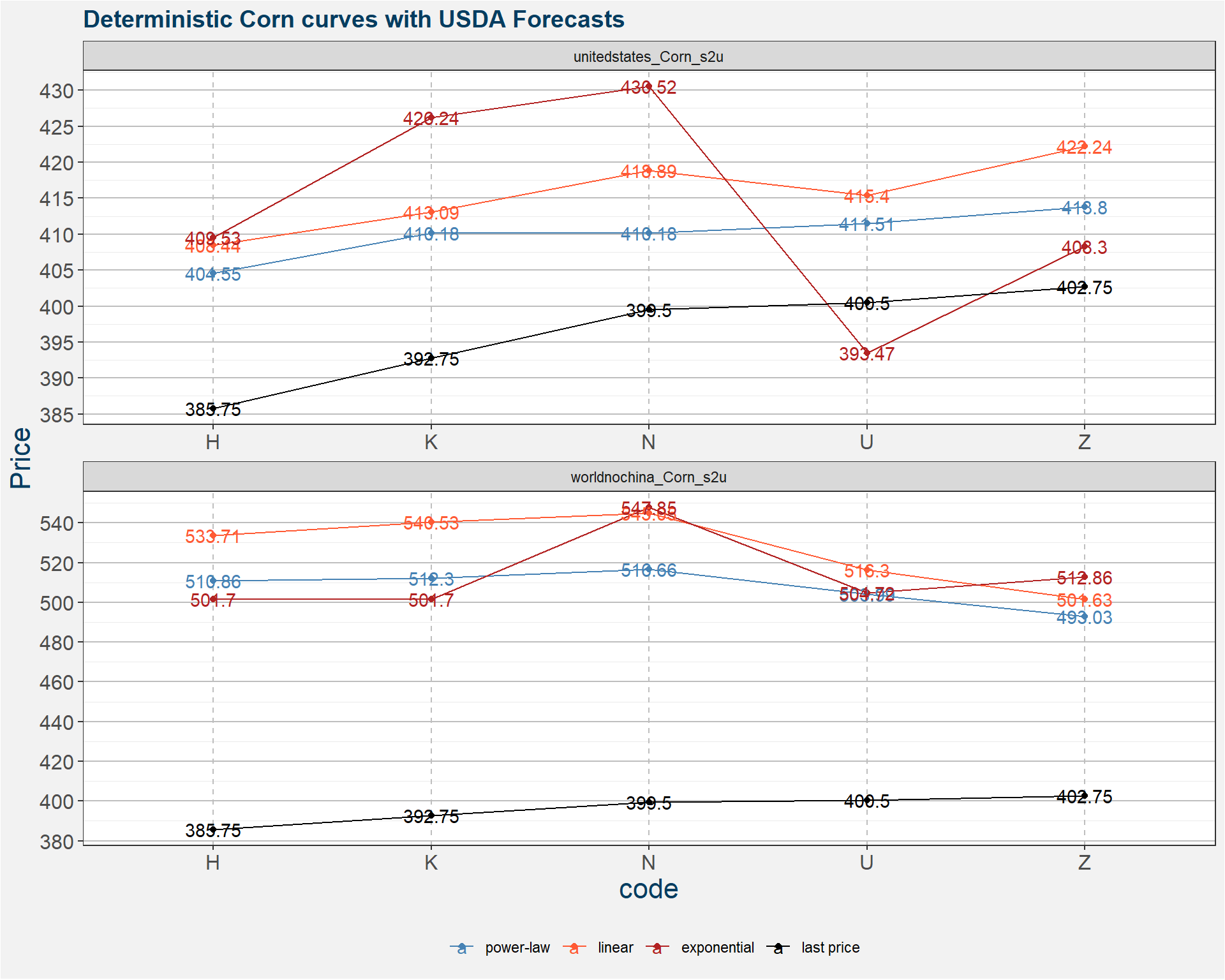
Taking the values from the table above we plot the model predictions in blue. The latest USDA United States stock-to-usage is given by the vertical orange line. The horizontal orange line gives the latest C N9 price. The results can be interpreted in two ways. If we take the USDA numbers as the truth we need to see a downward adjustment in price. On the other hand we can imply a stock-to-usage from the latest price. Currently this number is much less than that reported by the USDA.
2.2 Deterministic Curve Prediction
3 Probabilistic Model
If we discretise the stock-to-usage percentages we are able to do some statistics on the values of the prices given stock-to-usage (or any other feature) in the discretised basket. In this way we can perform Bayesian statistics on the prices, i.e. given a forcast on the stock-to-usage we can determine the probability that the price is contained withing some interval.
In the subsections below we show plots of the price statistics when the value of the underlyiing feature falls within the bucket specified on the x-axis. The solid black line shows the median price. The light and dark shaded regions show the 10th to 90th and 25th to 75th percentiles. The fat of the distributions lie withing the dark shaded region. For reference we also show the USDA and Polar Star fundamental forecast together with the latest price data. These are represented by the vertical and horizontal lines respectively. The same data used to create the images is also given in tabular form below the plots.
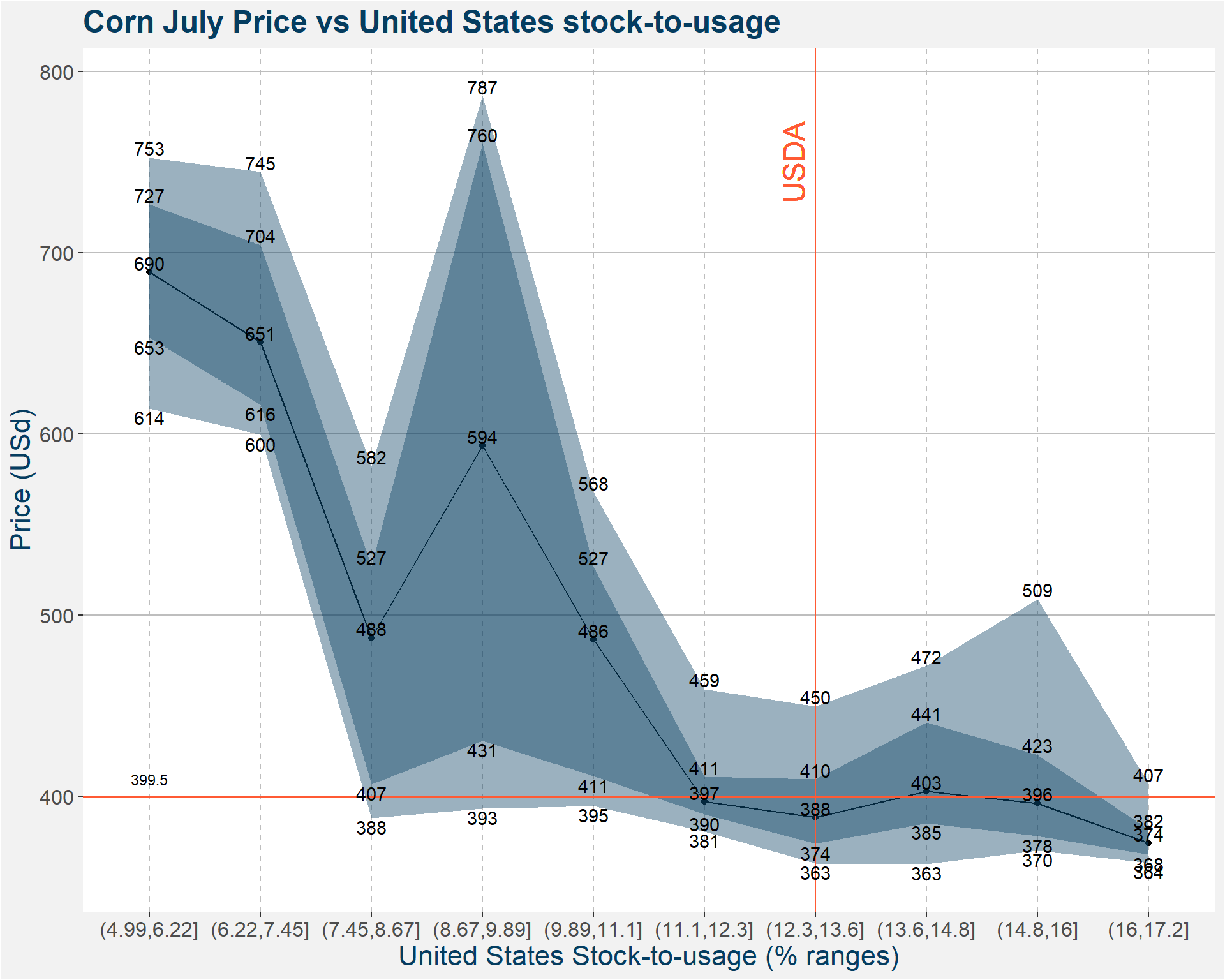
| p10 | p25 | p50 | p75 | p90 | |
|---|---|---|---|---|---|
| (4.99,6.22] | 614.325 | 653.125 | 689.500 | 726.7500 | 752.725 |
| (6.22,7.45] | 599.550 | 616.250 | 650.750 | 704.5000 | 744.700 |
| (7.45,8.67] | 388.000 | 406.625 | 487.500 | 527.0000 | 582.500 |
| (8.67,9.89] | 393.300 | 430.750 | 593.750 | 760.2500 | 786.600 |
| (9.89,11.1] | 394.800 | 411.125 | 486.500 | 526.6250 | 568.050 |
| (11.1,12.3] | 380.700 | 390.000 | 397.250 | 410.7500 | 459.300 |
| (12.3,13.6] | 363.150 | 373.750 | 388.375 | 409.5000 | 449.775 |
| (13.6,14.8] | 362.750 | 385.125 | 402.750 | 440.6875 | 472.075 |
| (14.8,16] | 370.000 | 378.000 | 396.250 | 423.0000 | 509.000 |
| (16,17.2] | 363.500 | 367.750 | 374.250 | 381.5000 | 406.850 |
3.1 World Stock-to-Usage

| p10 | p25 | p50 | p75 | p90 | |
|---|---|---|---|---|---|
| (9.89,11.5] | 625.600 | 661.2500 | 694.750 | 726.7500 | 747.300 |
| (11.5,13.2] | 398.000 | 549.2500 | 619.500 | 667.0000 | 779.000 |
| (13.2,14.8] | 378.750 | 392.3125 | 447.625 | 521.2500 | 578.925 |
| (14.8,16.4] | 371.000 | 397.1250 | 423.000 | 464.7500 | 511.700 |
| (16.4,18.1] | 364.500 | 376.7500 | 387.500 | 402.7500 | 440.800 |
| (18.1,19.7] | 364.950 | 371.2500 | 385.500 | 398.5625 | 412.775 |
| (19.7,21.3] | 363.725 | 370.5625 | 396.250 | 405.7500 | 448.775 |
| (21.3,23] | 361.550 | 364.3125 | 370.625 | 373.2500 | 374.250 |
| (24.6,26.2] | 399.500 | 399.5000 | 399.500 | 399.5000 | 399.500 |
3.2 World Stock-to-Usage without China

| p10 | p25 | p50 | p75 | p90 | |
|---|---|---|---|---|---|
| (7.15,8.08] | 644.000 | 685.2500 | 710.750 | 733.0000 | 756.500 |
| (8.08,8.99] | 588.300 | 611.0000 | 641.250 | 663.2500 | 703.400 |
| (8.99,9.91] | 383.800 | 394.4375 | 406.250 | 484.1250 | 520.125 |
| (9.91,10.8] | 384.500 | 392.2500 | 409.750 | 507.0000 | 773.250 |
| (10.8,11.7] | 369.000 | 381.3750 | 403.500 | 451.2500 | 556.550 |
| (11.7,12.7] | 359.475 | 373.3125 | 402.125 | 440.6875 | 547.875 |
| (12.7,13.6] | 367.250 | 377.5000 | 392.625 | 424.6875 | 486.875 |
| (13.6,14.5] | 364.700 | 369.2500 | 385.500 | 405.0000 | 421.400 |
| (14.5,15.4] | 384.700 | 392.5000 | 403.750 | 412.5000 | 486.900 |
| (15.4,16.3] | 369.150 | 380.5000 | 396.250 | 405.3750 | 412.600 |
3.3 Mean Crude
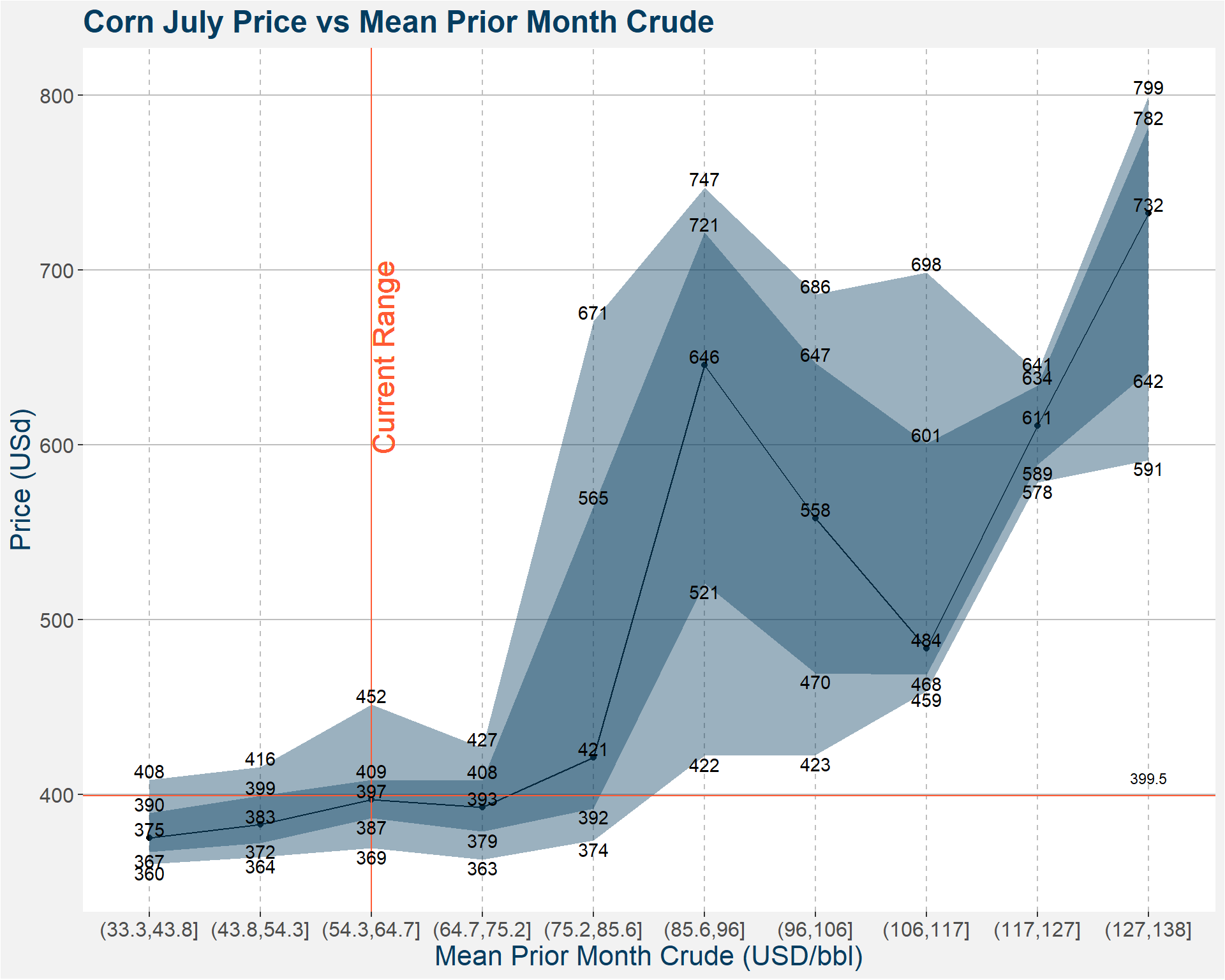
| p10 | p25 | p50 | p75 | p90 | |
|---|---|---|---|---|---|
| (33.3,43.8] | 360.250 | 367.2500 | 375.250 | 389.5000 | 408.500 |
| (43.8,54.3] | 364.250 | 372.5000 | 382.750 | 399.2500 | 415.675 |
| (54.3,64.7] | 369.425 | 386.5625 | 397.250 | 408.5625 | 451.500 |
| (64.7,75.2] | 363.000 | 378.7500 | 392.750 | 408.1250 | 426.650 |
| (75.2,85.6] | 373.750 | 392.1875 | 421.375 | 565.0000 | 670.875 |
| (85.6,96] | 422.275 | 520.9375 | 645.500 | 721.2500 | 747.000 |
| (96,106] | 422.750 | 469.5000 | 558.125 | 646.6875 | 685.875 |
| (106,117] | 459.250 | 468.5000 | 483.750 | 600.6250 | 698.450 |
| (117,127] | 578.475 | 588.8125 | 611.000 | 633.6875 | 641.350 |
| (127,138] | 591.275 | 641.9375 | 732.500 | 782.1250 | 799.450 |
3.4 Dollar Index
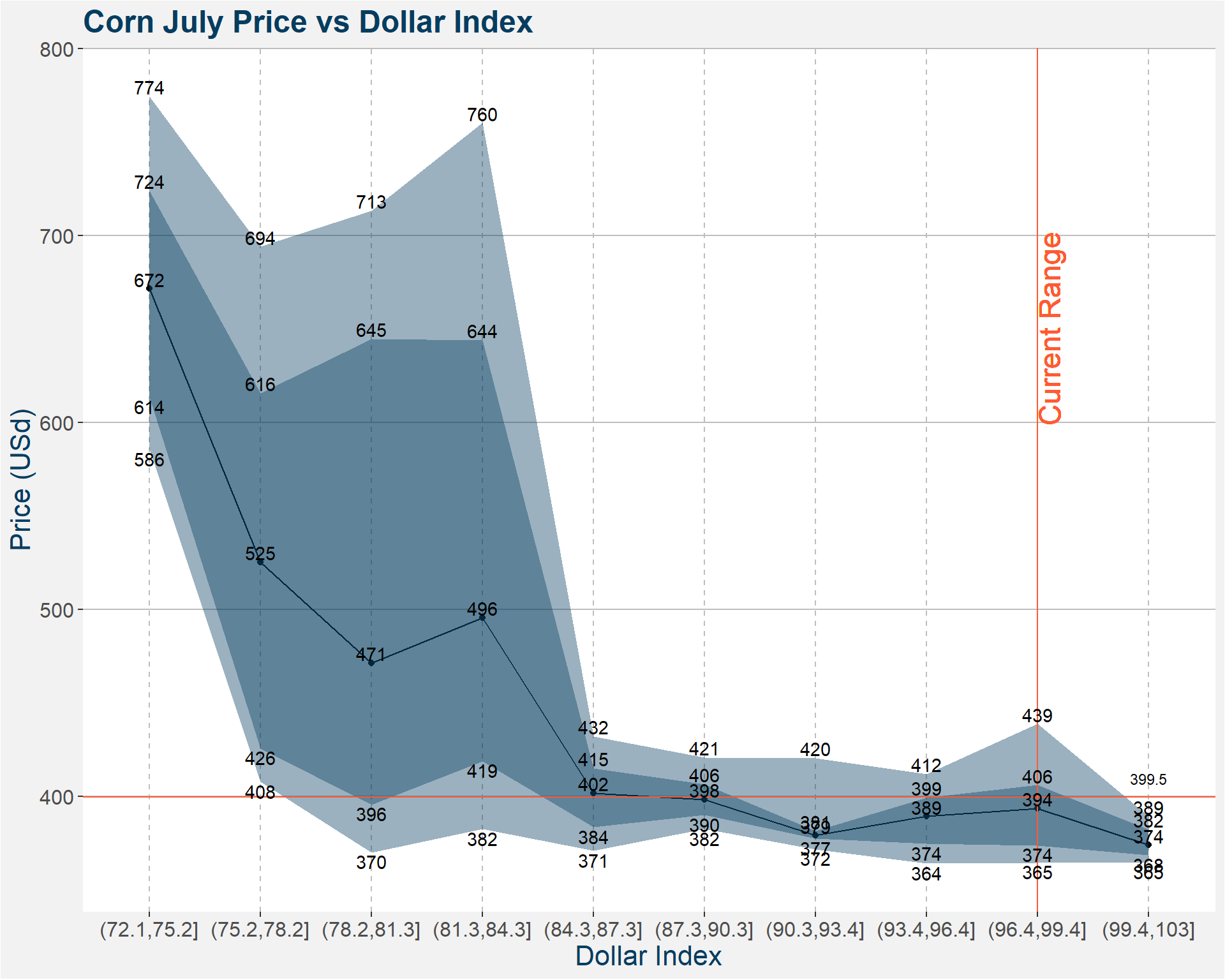
| p10 | p25 | p50 | p75 | p90 | |
|---|---|---|---|---|---|
| (72.1,75.2] | 585.550 | 613.500 | 671.500 | 724.0000 | 774.400 |
| (75.2,78.2] | 407.750 | 425.625 | 525.250 | 615.7500 | 694.000 |
| (78.2,81.3] | 370.000 | 395.625 | 471.250 | 644.6875 | 713.425 |
| (81.3,84.3] | 382.375 | 418.750 | 495.625 | 643.9375 | 760.250 |
| (84.3,87.3] | 370.750 | 383.500 | 401.750 | 415.0000 | 432.000 |
| (87.3,90.3] | 382.500 | 390.000 | 398.250 | 406.5000 | 420.700 |
| (90.3,93.4] | 371.750 | 377.250 | 379.000 | 381.3750 | 420.500 |
| (93.4,96.4] | 364.000 | 374.500 | 389.250 | 399.3125 | 411.975 |
| (96.4,99.4] | 364.575 | 373.750 | 393.500 | 405.9375 | 438.725 |
| (99.4,103] | 364.550 | 368.500 | 373.875 | 382.1250 | 389.200 |
4 Ensemble Model
We have created ensemble machine learning models that predict the corn price along the futures curve. These models take as inputs the stock-to-usage percentages of the top corn producing and consuming nations together with the dollar index and month prior average crude price as proxies for the US Dollar and energy respectively.
The ensemble models we create are all random forest regression models. We create a train and test split and perform hyper parameter tuning on the training set using 3 fold cross-validation. Within the training data we perform oversampling to the less representative feature ranges. Fore more information of how to perform oversampling correctly we refer the interested reader to this link. Ensemble models are a natural extension of the single variable deterministic models in that they are able to gain predictive quality from possible interactions between the different input features.
From the best models we determine the variable importance of all the input features. The results are sumarised in the plot below. The greater the importance the larger the effect of that feature on the predicted values. The dashed red line shows the value of importance if all the features were equally important.

Notice that the features with greatest importance is unitedstates_Corn_s2u. In all the cases shown above this feature makes up more than 50% of the variable importance of the ensemble models. The table below gives the R-squared values of the ensemble models fitted to the data. Notice the significant improvement over the deterministic models.
| R squared | |
|---|---|
| N | 0.84 |
| U | 0.76 |
| Z | 0.77 |
| H | 0.85 |
| K | 0.92 |
4.1 United States Stock-to-Usage Sensitivity
As the United States Stock-to-Usage percentages increase we expect the price of corn to decrease. This intuition is confirmed in the plots below. The y-and x-axis show the model prediction and value of United States Stock-to-Usage respectively. Here we fix all parameters to the latest WASDE numbers, but allow the value of United States Stock-To-Usage the change from 5 to 20. In the plots below we see the quasi monotonic decreasing relationship between the two variables. We can also see transition values that resembles a phase transition for values of United States Stock-to-Usage around 10.
To obtain the plot below we aggregate all the sensitivity results all along the curve. The horizontal line showing the latest price is the mean value along the curve. The idea is to give a feel for what range of United States stock-to-usage numbers will result in large price moves.
4.2 World Stock-to-Usage Sensitivity
As the World Stock-to-Usage percentages increase we expect the price of corn to decrease. This intuition is confirmed in the plots below. The y-and x-axis show the prediction and value of World Stock-to-Usage respectively. Here we fix all parameters to the latest WASDE numbers, but allow the value of World Stock-To-Usage the change from 10 to 40. In the plots below we see the quasi monotonic decreasing relationship between the two variables. We can also see transition values that resembles a phase transition for values of World Stock-to-Usage around 13 to 14.
4.3 World Stock-to-Usage without China Sensitivity
As the World without China Stock-to-Usage percentages increase we expect the price of corn to decrease. This intuition is confirmed in the plots below. The y-and x-axis show the prediction and value of World without China Stock-to-Usage respectively. Here we fix all parameters to the latest WASDE numbers, but allow the value of World Stock-To-Usage the change from 10 to 40. In the plots below we see the quasi monotonic decreasing relationship between the two variables. We can also see transition values that resembles a phase transition for values of World without China Stock-to-Usage around 9 to 13.
4.4 Crude Sensitivity
As the cost of energy increases we expect the price of corn to increase. This intuition is confirmed in the plots below. The y-and x-axis show the prediction and value of crude respectively. Here we fix all parameters to the latest WASDE numbers, but allow the value of the prior month crude price the change from 40 to 80. In the plots below we see the monotonic increasing relationship between the two variables. We can also see an elbow forming at crude prices greater than 75.
5 Only Crude, US and World Stocks
Here we focus on the three features with the greaterst feature importances,
- US stocks,
- World stock, and
- crude.
Below we show the feature importances of the reduced models.
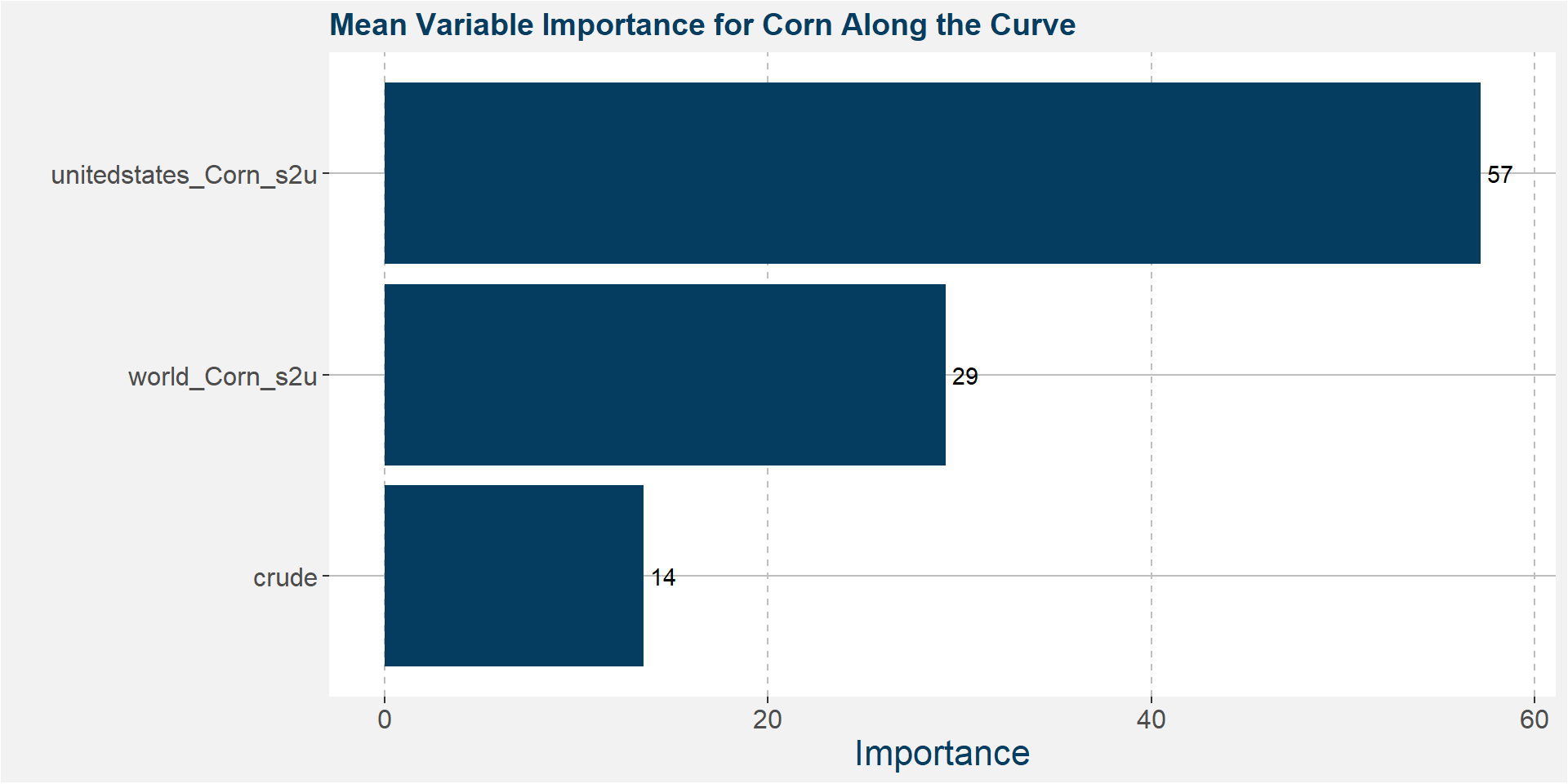
Notice that the features with greatest importance is unitedstates_Corn_s2u. The table below gives the R-squared values of the ensemble models fitted to the data. Notice the significant improvement over the deterministic models.
| R squared | |
|---|---|
| N | 0.79 |
| U | 0.73 |
| Z | 0.66 |
| H | 0.83 |
| K | 0.88 |
6 Model predictions given USDA numbers
The plot below shows the ensemble model predictions for USDA forecasted fundamentals. It is difficult to pin down the value of crude, so we consider a range of values form 50 to 60. Furthermore we consider all the predictions from each of the decision tree models to determine prediction statistics. The normal output of a collection of regression trees is the mean of all the predictions. In the plot below we show the 25th to 75th percentiles of the predicted prices, this corresponds to the area between the two gray curves. The latest price data is represented by the black curve. The median model prediction is shown in blue. here we use the median as it is les likely to be skewed by possible outliers.
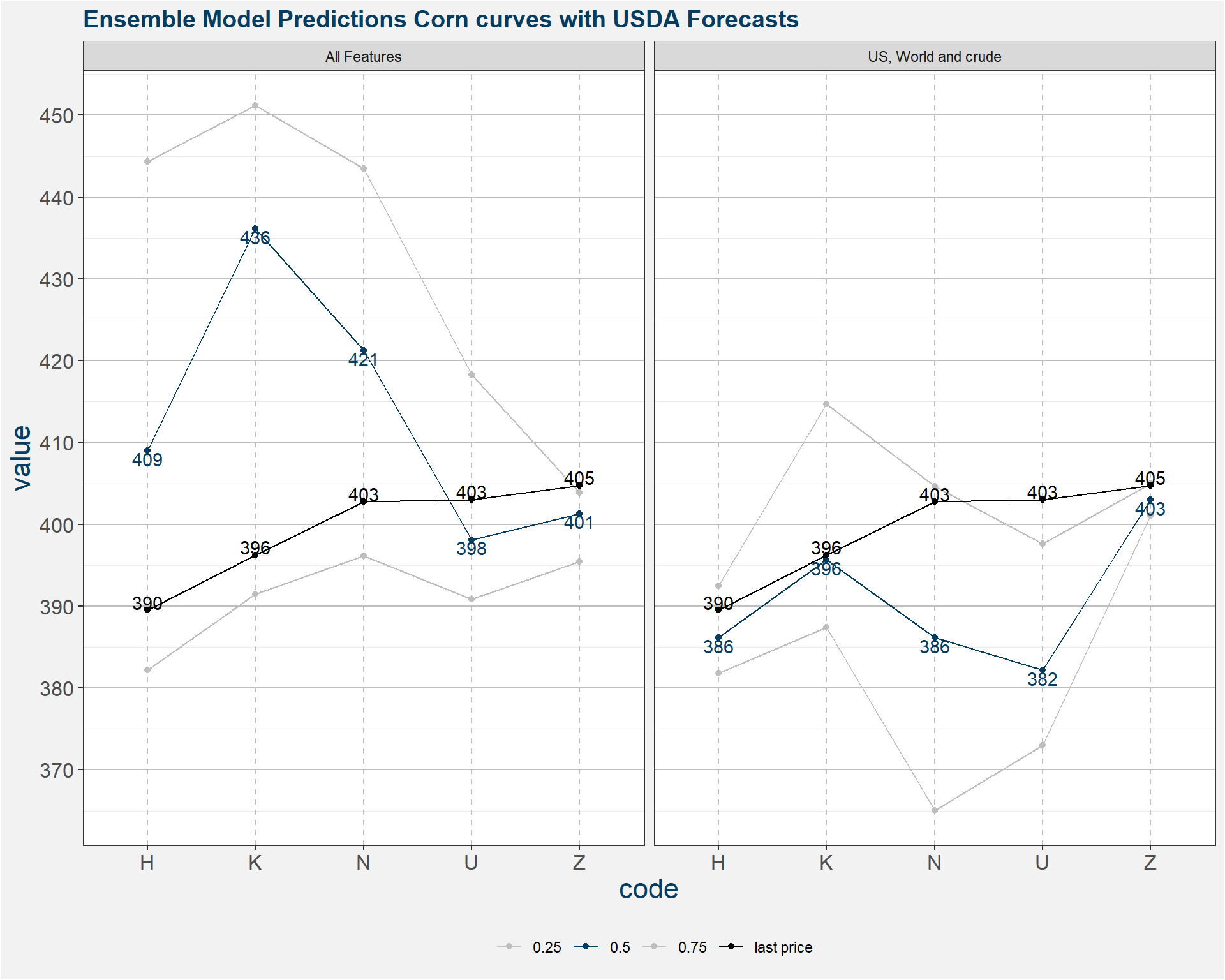
From the images above the corn prices are more or less aligned with the current fundamentals. There might be an opportunity on the downside in N and U.